asr_eval.align¶
Tools for string alignment to evaluate speech recognition quality.
Some main utilities:
ParserandDEFAULT_PARSERto parse predictions and annotations (possibly multivariant), which may include normalization, lowercase and diacritic conversion, splitting into words and punctuation removal.Transcriptionas a format for parsed transcription.Alignmentto align predictions against multivariant annotations and calculate metrics.solve_optimal_alignment()as the underlying optimal alignment algorithm via dynamic programming.DatasetMetricandbootstrap()to calculate average metrics with uncertainty via bootstrapping.error_listing()to perform fine-grained error analysis.MultipleAlignmentto visually compare multiple predictions for the same ground truth.char_align()to align strings on a character level.fill_word_timings_inplace()to fill word timings via forced alignment usingCTCmodels.
- class asr_eval.align.alignment.Alignment(true, pred, absorb_insertions=True)[source]¶
A word-to-word alignment between ground truth and prediction.
The constructor internally runs
solve_optimal_alignment(), then places each of the predicted words into one of theslots. Each slot represents a specific position in the ground truth: before, at or after a word in the ground truth. See more examples and details in the user guide: Alignments and WER.Example
>>> from asr_eval.align.alignment import Alignment >>> from asr_eval.align.parsing import DEFAULT_PARSER >>> true = 'Nothing hi there {one|1} {two|2} {eh} ok' >>> pred = 'No thing hi there one to eh oh' >>> true_parsed = DEFAULT_PARSER.parse_transcription(true) >>> pred_parsed = DEFAULT_PARSER.parse_single_variant_transcription(pred) >>> alignment = Alignment(true_parsed, pred_parsed) >>> # calculating WER >>> metrics, err_listing = alignment.error_listing() >>> metrics.word_error_rate() 0.6666666666666666
>>> # visualizing (run pip install jupyter to render HTML) >>> from IPython.display import HTML >>> from asr_eval.align.alignment import MultipleAlignment >>> ma = MultipleAlignment(true_parsed, {'pred': alignment}) >>> HTML(ma.render_as_text(color_mode='html'))
- Parameters:
true (
Transcription) – The first text to align, usually a ground truth. May be multivariant or single-variant, may includeWildcardinsertions.pred (
SingleVariantTranscription) – The second text to align, usually a prediction. Note that while the underlying alignment algorithmsolve_optimal_alignment()supports both texts to be multivariant, this class requires a single-variant prediction.absorb_insertions (
bool) – If true, searches for insertions in “pre” slots (before or after ground truth words) and moves them into a neighbour “at” slot if this reduces CER. See the user guide Alignments and WER for details.
- true: TranscriptionPath¶
The parsed ground truth with selected path (i. e. a selected option index in each multivariant block, if such blocks exist).
- pred: SingleVariantTranscription¶
The parsed prediction, as passed into the constructor.
- slots: dict[OuterLoc | InnerLoc, list[Correct | Replacement | Insertion | Deletion]]¶
The predicted words which are packed into slots. Each slot represents a specific position in the ground truth: before, at or after a word in the ground truth. See Alignments and WER for details.
- error_listing(count_absorbed_insertions=True, max_consecutive_insertions=None, skip_slots_with_zero_errors=True)[source]¶
Return WER metrics and detailed error positions.
The first returned value is overall
Metricskeeping a number of replacements, deletions and insertions. The WER value can be further obtained byword_error_rate().The second returned value contains more detailed error analysis: a mapping from the ground truth outer slot (see the Alignments and WER for details about slots) to
ErrorListingElement. This may help in tasks such as error visualizing and fine-grained analysis.See examples in the
ErrorListingElementdocs.- Parameters:
max_consecutive_insertions (
int|None) – If set to integer N, in cases when more than N consecutive insertions occur between two words from the ground truth, count them as exactly N insertions. This helps to stabilize metric in the presence of ostillatory hallucinations, when the same word is repeated until the generation limit is reached. Also, this aligns better with common sense, where 100 insertions in a row is not as big a problem as 100 different errors in different places.count_absorbed_insertions (
bool) – If the alignment was constructed withabsorb_insertions=True, should we count or skip the absorbed insertions? For example, in “nothing” vs “no thing”, we will get a total of 2 errors withcount_absorbed_insertions=Trueand 1 error withFalse. In the later case, our “WER” metric is different from the usual meaning, but is arguably better. However, the effect is often negligible.skip_slots_with_zero_errors (
bool) – If True, will omit all theerrors. (slots where there are zero word)
- Return type:
tuple[Metrics,dict[OuterLoc,ErrorListingElement]]
- render_as_text(color_mode='ansi', html_add_style=True, max_cell_size=100, name='pred')[source]¶
Visualizes the alignment. Returns a string containing the lines: the ground truth and the prediction.
nameargument specifies how the prediction will be titled in the output string. If None, will not add name.For other arguments, see
render_as_text().- Return type:
str- Parameters:
color_mode (Literal['ansi', 'html', None])
html_add_style (bool)
max_cell_size (int | None)
name (str | None)
- class asr_eval.align.alignment.MultipleAlignment(baseline, alignments, elapsed_times=<factory>, baseline_name='true')[source]¶
A dataclass representing a group of multiple predicted texts aligned against the same ground truth text.
Useful for displaying and aggregating purposes. May also store elapsed times if we want to compare several models by WER and inference time.
For unlabeled data, all the predicted texts may be aligned against another predicted text (a shared baseline), in this case
baseline_namecontains its name, and theMultipleAlignmentis considered unlabeled.Example
>>> from asr_eval.align.alignment import Alignment >>> from asr_eval.align.parsing import DEFAULT_PARSER >>> from asr_eval.align.alignment import MultipleAlignment >>> true = 'hey <*> {eh} one dollar' >>> preds = { ... 'first': 'Hey eh dollar', ... 'second': 'hey one dollar', ... 'third': 'Hey one dollar AB AB', ... 'fourth': 'Hey one dollar AB AB AB AB', ... 'fifth': '1 dollar!', ... } >>> true_parsed = DEFAULT_PARSER.parse_transcription(true) >>> alignments = { ... name: Alignment(true_parsed, ... DEFAULT_PARSER.parse_single_variant_transcription(pred)) ... for name, pred in preds.items() ... } >>> ma = MultipleAlignment(true_parsed, alignments) >>> print(ma.render_as_text(color_mode=None)) true | hey <*> {eh} one dollar first | Hey eh dollar second | hey one dollar third | Hey one dollar AB AB fourth | Hey one dollar AB AB AB AB fifth | 1 dollar >>> ma.render_as_text(color_mode='html') '...'
The examples show that the alignment is still not ideal for predictions 4 and 5. In the 4-th prediction, the visually best alignment would give 4 word errors, and the current alignment gives 2 errors, so, the goal to achieve a minimum number of word errors is to blame for this. In the 5-th prediction, the algorithm is not clever enough to known that “1” is closer to “one” than to “Hey”. In this case, a multivariant annotation “{one|1}” or text normalization would help.
- Parameters:
baseline (Transcription)
alignments (dict[str, Alignment])
elapsed_times (dict[str, float])
baseline_name (str | Literal['true'])
- baseline: Transcription¶
The baseline against which all the predictions are aligned. Usually a ground truth.
- elapsed_times: dict[str, float]¶
The inference times for each prediction (may be NaN or absent).
- baseline_name: str | Literal['true'] = 'true'¶
The baseline name. Equals “true” when baseline is ground truth, otherwise an name of the
baselineprediction against which other predictions are aligned.
- to_dataframe()[source]¶
Convert into a table view.
For N alignments and M slots in the baseline (ground truth), returns NxM table. All the predicted words fill the table, in form of lists of
list[WORD_ERROR_TYPE]. This is similar to Multiple Sequence Alignment (MSA) in biology and is used as an intermediate step inrender_as_text().- Return type:
DataFrame
- to_table()[source]¶
Convert into a table view, but using a better typed
Table2Dinstead ofpd.DataFrame, compared toto_dataframe().- Return type:
Table2D[list[Correct|Replacement|Insertion|Deletion]]
- render_as_text(color_mode='ansi', html_add_style=True, add_prediction_names=True, max_cell_size=100, charwise_mode=_CHARWISE_RENDER)[source]¶
Visualizes all the alignments against the baseline (ground truth) as a multiline string.
- Parameters:
color_mode (
Literal['ansi','html',None]) – Colorize errors with ANSI color codes (“ansi”) or html tags (“html”).html_add_style (
bool) – If True andcolor_mode="html", wraps the result in a <span> html tag with “white-space: pre” and monospace font. Such a font is important for visual alignment.add_prediction_names (
bool) – If true, prepends lines with prediction names, as provided in thealignments.max_cell_size (
int|None) – Trims words larger than the specified size. May be useful for models that occasionally generate infinitely long words up to the generation limit.charwise_mode (
bool) – Whether to disable separating words by space visually and mark deletions by a special character instead of space. Turn on for character-wise alignment.
- Return type:
str
In the visualization, the outer slots of the baseline (i. e. words, gaps between them and multivariant blocks) are “columns”, and predictions are rows.
See example in the class docs.
- class asr_eval.align.alignment.ErrorListingElement(outer_loc, true, true_text, pred, n_replacements, n_insertions, n_deletions, sample_id=None)[source]¶
Info about errors for a specific slot in the ground truth transcription.
Note
This class enables fine-grained error analysis and is not needed if you only want to calculate WER.
See more info about slots in the user guide: Alignments and WER. In short, each slot represents a specific position in the ground truth: before, at or after a word in the ground truth.
ErrorListingElementkeeps a list of insertions, deletions or replacements for a specific slots. Thus, it represents errors made in the specific place of the ground truth transcription. Note that there may be multiple predicted words for a single slot (for example, a multi-word insertion), and thus multiple errors. Therefore,.predfield contains a list of errors.The
ErrorListingElementmay additionally keep a.sample_id. We can gather error listings from many samples and merge them into a jointlist[ErrorListingElement]. This list represents a full error statistics on a dataset. We can group the list by.true_textfield and obtain error statistics for different words. This is what happening incompare_pipelines()that is used by a dashboard.Example
>>> from collections import defaultdict >>> from asr_eval.align.alignment import Alignment, ErrorListingElement >>> from asr_eval.align.parsing import DEFAULT_PARSER >>> from asr_eval.align.metrics import Metrics ... >>> truth_and_predictions = [ ... ('Alexa, turn the light on.', 'alex turns the light on'), ... ('Alexa, scenario off.', 'alex scene area off'), ... ('Alexa, play music.', 'alexa play music'), ... ('Alexa, turn if off, thanks.', 'alex turns if off thanks'), ... ('Alexa, hello!', 'alexa hello'), ... ] ... >>> metrics = Metrics() >>> errors: dict[str, list[ErrorListingElement]] = defaultdict(list) >>> for true, pred in truth_and_predictions: ... alignment = Alignment( ... DEFAULT_PARSER.parse_single_variant_transcription(true), ... DEFAULT_PARSER.parse_single_variant_transcription(pred), ... ) ... metric, listing = alignment.error_listing( ... skip_slots_with_zero_errors=False) ... metrics += metric # uses Metrics.__add__ overloading ... for listing_element in listing.values(): ... if listing_element.true_text is not None: ... errors[listing_element.true_text].append(listing_element) >>> print(metrics) Metrics(true_len=18, n_replacements=6, n_insertions=1, n_deletions=0)
>>> for word, error_statistics in errors.items(): ... good_cases = [x for x in error_statistics if x.n_errors == 0] ... bad_cases = [x for x in error_statistics if x.n_errors > 0] ... if len(bad_cases): ... print( ... f'{word}: {len(good_cases)} correct, {len(bad_cases)}' ... f' wrong: {[x.pred_text for x in bad_cases]}' ... ) alexa: 2 correct, 3 wrong: ['alex', 'alex', 'alex'] turn: 0 correct, 2 wrong: ['turns', 'turns'] scenario: 0 correct, 1 wrong: ['scene']
- Parameters:
outer_loc (OuterLoc)
true (Token | MultiVariantBlock | None)
true_text (str | None)
pred (list[Correct | Replacement | Insertion | Deletion])
n_replacements (int)
n_insertions (int)
n_deletions (int)
sample_id (int | None)
- outer_loc: OuterLoc¶
An outer slot in the ground truth transcription. See more info about slots in the user guide: Alignments and WER.
- true: Token | MultiVariantBlock | None¶
For an “at” slot contains the corresponding block. For a “pre” slot is None.
- true_text: str | None¶
A joint ground truth text for the given slot. For a “pre” slot is None.
- pred: list[Correct | Replacement | Insertion | Deletion]¶
A list of everything that was predicted for the current slot. May contain correct matches, insertions, deletions or replacements.
- n_replacements: int¶
Number of
Replacementelements in the.pred.
- n_insertions: int¶
Number of
Insertionelements in the.pred, which may be clipped above bymax_consecutive_insertionsparameter or corrected bycount_absorbed_insertionsparameter oferror_listing().
- sample_id: int | None = None¶
A sample id in the dataset, is None by default and can be filled manually.
- property n_errors: int¶
A sum of n_replacements, n_insertions and n_deletions.
- property pred_text: str¶
A joint predicted text obtained from
.predfield.
- asr_eval.align.alignment.WORD_ERROR_TYPE = asr_eval.align.alignment.Correct | asr_eval.align.alignment.Replacement | asr_eval.align.alignment.Insertion | asr_eval.align.alignment.Deletion¶
A union of wrappers that store a
Tokenand an associated error type.
- class asr_eval.align.alignment.Deletion[source]¶
One of the error types in
error_listing()
- class asr_eval.align.alignment.Correct(token)[source]¶
One of the error types in
error_listing()- Parameters:
token (Token)
- class asr_eval.align.alignment.Replacement(token)[source]¶
One of the error types in
error_listing()- Parameters:
token (Token)
- class asr_eval.align.alignment.Insertion(token)[source]¶
One of the error types in
error_listing()- Parameters:
token (Token)
- class asr_eval.align.parsing.Parser(tokenizing='\\\\w+|[^\\\\w\\\\s\\\\., !\\\\?: ;…\\\\-‑–—\\'"‘“”«»\\\\(\\\\)\\\\[\\\\]\\\\{\\\\}]+', preprocessing=<function Parser.<lambda>>, postprocessing=<function Parser.<lambda>>)[source]¶
Parses into words and (optionally) normalizes prediction or annotation.
Performs the following:
Preprocesses the whole text if
preprocessingis set. This stage is suitable for various normalization methods, if they are used, such as numerals-to-digits normalizers or filler words removers.If
parse_transcription(), is called, processes multivariant syntax.Splits all the text blocks into words with a regexp stored in the
tokenizingattribute.Postprocesses each word if
postprocessingis set. This stage is suitable for lowercase conversion.
A
DEFAULT_PARSERis an instance of the Parser with default parameters.Example
Hi there {fourth|4|4-th} {eh} <*>>>> from asr_eval.align.parsing import DEFAULT_PARSER # same as Parser() >>> text = 'Hi there {fouth|4|t-th} {eh} <*>' >>> parsed = DEFAULT_PARSER.parse_transcription(text) >>> print(parsed.blocks) (Token(hi), Token(there), MultiVariantBlock([Token(fouth)], [Token(4)], [Token(t), Token(th)]), MultiVariantBlock([Token(eh)], []), Token(Wildcard())) >>> from dataclasses import asdict >>> asdict(parsed.blocks[0]) {'value': 'hi', 'uid': 'id0', 'start_pos': 0, 'end_pos': 2, 'start_time': nan, 'end_time': nan, 'attrs': {}, 'flags': set()} >>> print(parsed.colorize())
Note
Why not just
nltk.word_tokenize? In asr_eval words keep references to their positions in the original text, whichword_tokenizedoes not support.By making a Parser with
tokenizing=r'\w|\s|[^\w\s{PUNCT}]'you can parse strings into characters, excluding punctuation. In this case,Alignmentwill calculate CER (character error rate) instead of WER.You can create named parsers in
asr_eval.bench.parsers.When labeling a dataset, the annotator should be aware of the tokenization scheme. For example, if
3/4$is tokenized as a single word, then3/4$and3 / 4 $(with spaces) are different options, and both should be included in a multivariant block. See Alignments and WER for details.
Words (and, in general, tokens) can have attributes (
attrs) and flags (flags). They are written in brackets, separated by comma from each other, and by “!” from the text. For example, the following syntax adds flag “abc” and attribute “w” with value “10” to the words bar, baz, qux:Example
>>> from asr_eval.align.parsing import DEFAULT_PARSER >>> text = '"Foo [abc,w=10! bar {baz} qux ]"' >>> transcription = DEFAULT_PARSER.parse_transcription(text) >>> for block in transcription.blocks: ... print(block) Token(foo) Token(bar, attrs:w=10, flags:abc) MultiVariantBlock([Token(baz, attrs:w=10, flags:abc)], []) Token(qux, attrs:w=10, flags:abc)
- Parameters:
tokenizing (str)
preprocessing (Callable[[str], str])
postprocessing (Callable[[str], str])
- tokenizing: str¶
A regexp to extract word, by default
\w+|[^\w\s{PUNCT}]+, wherePUNCTare punctuation characters.
- preprocessing()¶
A text preprocessing method set as
Callable[[str], str], by default does nothing. Is suitable for text-to-text operations such as normalizers or filler word removers. Note that after parsing thetextfield inTranscriptionwill contain the preprocessed version, and the original version will be gone.Example
>>> from asr_eval.align.parsing import Parser >>> import re >>> def filler_remover(text: str) -> str: ... for word in 'eh', 'oh', 'umm': ... text = re.sub(word, '', text, flags=re.IGNORECASE) ... return text >>> parser = Parser(preprocessing=filler_remover) >>> parsed = parser.parse_transcription('Umm eh of course') >>> print(parsed.text, parsed.blocks) of course [Token(of), Token(course)]
See more examples in
asr_eval.bench.parsers.
- postprocessing()¶
A word postprocessing method set as
Callable[[str], str], by default performs lowercase and diacritic conversion:postprocessing=lambda text: text.lower().replace('ё', 'е')
Will only affect the
valuefield inToken. This is useful to match lowercase words, while tracking their positions in the originaltextwith capitalization and punctuation.
- parse_single_variant_transcription(text)[source]¶
Parses a text without multivariant blocks.
In general, one needs this method for typing purposes only, because
parse_transcription()supports both multivariant and single-variant transcriptions.- Return type:
- Parameters:
text (str)
- asr_eval.align.parsing.PUNCT¶
A default set of punctuation characters to exclude from words
.,!?:;…-‑–—'"‘“”«»()[]{}. Note that this does not affect parsing control characters “{”, “|”, “}” in multivariant syntax. To override, create aParserwith customtokenizingfield.
- class asr_eval.align.transcription.Transcription(text, blocks)[source]¶
A transcription that is normalized and parsed into words.
Typically constructed via
parse_transcription(). May contain zero or more multivariant blocks orWildcardinsertions. Stores .text field (the original text) and list of tokens (words) that keep references to the positions in the original text.Has a subclass
SingleVariantTranscriptionused for typing clarity where we do not expect multivariance (mainly for predictions). Typically constructed viaparse_single_variant_transcription().Example
>>> from asr_eval.align.parsing import DEFAULT_PARSER >>> transcription = DEFAULT_PARSER.parse_transcription( ... "Alexa skip to friday {skip to friday} " ... ", {Don't|Do not} need another sad day <*>" ... ) >>> print(transcription.blocks) (Token(alexa), Token(skip), Token(to), Token(friday), MultiVariantBlock([Token(skip), Token(to), Token(friday)], []), MultiVariantBlock([Token(don), Token(t)], [Token(do), Token(not)]), Token(need), Token(another), Token(sad), Token(day), Token(Wildcard()))
>>> from IPython.display import HTML >>> HTML(transcription.colorize(color_mode='html'))
Transcription tokens can have attributes and flags, see examples in the
Parserdocs, see also fieldsattrsandflags.- Parameters:
text (str)
blocks (tuple[Token | MultiVariantBlock, ...])
- text: str¶
The original text that was parsed into words.
- blocks: tuple[Token | MultiVariantBlock, ...]¶
For single-varian transcription is a list of
Token. For multivariant transcription may also contain zero or moreMultiVariantBlock.
- list_all_tokens()[source]¶
Iterates over all the tokens, including ones in multivariant blocks.
- Return type:
Iterator[Token]
- is_timed()[source]¶
A transcription can become timed, if we fill time (in seconds) for all the words. This can be done with
fill_word_timings_inplace(). Otherwiseis_timedis False.- Return type:
bool
- get_starting_part(time)[source]¶
Cut a timed transcription up to the specified time. Is primarily used for streaming evaluation of partial transcriptions.
A transcription is timed if all the tokens have their
start_timeandend_timefilled with not-NaN values. The current method selects only the tokens up to the specified time.If
timeis inside a token, converts it into a multivariant block with options[token]and[]. For example, letblocks = [A, B], tokenAspans from 1.0 to 2.0 andBspans from 3.0 to 4.0. Thenget_starting_part(time=3.5)returns[A, MultiVariant(X)], whereX == [[B], []].If
timeis inside an existing multivariant block, then cuts each option up to thetime, and iftimeis inside some token in some option, add another option with this token excluded. For example, letblocks = [A, MultiVariant([[B1], [B2, B3]])], andB1spans from 3.0 to 4.0,B2spans from 3.0 to 3.5,B3spans from 3.5 to 4.0. Thenget_starting_part(time=3.7)returns[A, MultiVariant(X)], whereX == [[], [B1], [B2], [B2, B3]]. Here[]was obtained from cutting option[B1]and[B2]was obtained from cutting option[B2, B3].Returns a copy without modifying the original object.
- Return type:
- Parameters:
time (float)
- colorize(color_mode='ansi')[source]¶
Colorizes each token in the parsed (possibly multivariant) string. Returns string with ANSI escape codes (rendered using
printin jupyter or console), or HTML color spans.See example in the
Alignmentdocstring.- Return type:
str- Parameters:
color_mode (Literal['ansi', 'html'])
- select_single_path(multivariant_choices)[source]¶
Returns a transcription with the selected option in each multivariant block.
Note
This is a lower-level function typically not called manually use
Alignment()constructor instead.The
multivariant_choicesare usually obtained fromsolve_optimal_alignment(). Themultivariant_choiceslength should equal the total count of multivariant blocks.- Return type:
- Parameters:
multivariant_choices (Sequence[int])
- class asr_eval.align.transcription.SingleVariantTranscription(text, blocks)[source]¶
Bases:
TranscriptionA subclass of
Transcriptionused for typing clarity where we do not expect multivariance (mainly for predictions). Typically constructed viaparse_single_variant_transcription().- Parameters:
text (str)
blocks (tuple[Token, ...])
- blocks: tuple[Token, ...]¶
For single-varian transcription is a list of
Token. For multivariant transcription may also contain zero or moreMultiVariantBlock.
- class asr_eval.align.transcription.Token(value, uid=<factory>, start_pos=0, end_pos=0, start_time=nan, end_time=nan, attrs=<factory>, flags=<factory>)[source]¶
Represents typically a single word or a
Wildcardsymbol in a transcription.Note
Typically you don’t need to create Token manually. They are created automatically when parsing a text with
Parser.Token is what the alignment algorithm considers an atom. Two tokens may be equal or not. If not equal, this contributes to the error count. By default
Parsersplits a text into words, and in this case each token is a words, and we obtain WER (word error rate) by aligning them. However, with modifiedtokenizingregexp a parser may split into characters - then each token stores a single character. See theParserdocs for defails. There is also a special token with.value=Wilcard()that matches every token equence, possibly empty.- Parameters:
value (str | Wildcard)
uid (str)
start_pos (int)
end_pos (int)
start_time (float)
end_time (float)
attrs (dict[str, Any])
flags (set[str])
- value: str | Wildcard¶
A text (usually a word) after all the normalization steps, or a
Wildcardsymbol. If not wilcard, two tokens match if their texts are equal as strings.
- uid: str¶
An ID that is unique in the text. Is used to refer the token.
- start_pos: int¶
The start position in the original text (the
.textfield of theTranscriptionthe token belongs to).
- end_pos: int¶
The end position in the original text (the
.textfield of theTranscriptionthe token belongs to), not inclusive.
- start_time: float¶
The start time in seconds, is NaN by default, can be filled by
fill_word_timings_inplace().
- end_time: float¶
The end time in seconds, is NaN by default, can be filled by
fill_word_timings_inplace().
- attrs: dict[str, Any]¶
Key-value attributes, most often empty.
May be used, for example, for word weights.
- flags: set[str]¶
Flags, most often empty.
May be used to flag specific words to evaluate on.
- property is_timed: bool¶
Are
start_timeandend_timenot NaN?
- class asr_eval.align.transcription.Wildcard[source]¶
Represents a Wilcard symbol <*> in a transcription that matches every word sequence, possibly empty.
- class asr_eval.align.transcription.MultiVariantBlock(options, start_pos=0, end_pos=0, uid=<factory>)[source]¶
A multivariant block in a transcription. Contains two or more options, each option contains zero or more tokens.
- Parameters:
options (list[list[Token]])
start_pos (int)
end_pos (int)
uid (str)
- start_pos: int¶
Start of the span in the original text, including braces {}.
- end_pos: int¶
End of the span the original text, including braces {}.
- uid: str¶
An ID that is unique in the text. Is used to refer the block.
- property start_time: float¶
The earliest
start_timeacross all options, or NaN if tokens are not timed.
- class asr_eval.align.transcription.TranscriptionPath(text, blocks, multivariant_choices, _choices_by_mvuid=<factory>, _uid_to_slot_loc=<factory>, _slot_locs=<factory>, _slot_loc_to_index=<factory>)[source]¶
Bases:
TranscriptionA Transcription with a selected option for each multivariant block.
Note
This is a lower-level subclass that extends
Transcriptionwith a few indexing methods that are typically not called manually. See theTranscriptiondocs for the main methods.See more details in Alignments and WER.
- Parameters:
- get_prev_slot(loc)[source]¶
A step backward: from the next slot to the previous.
Returns None if we reached the end.
- get_next_slot(loc)[source]¶
A step forward: from the previous slot to the next.
Returns None if we reached the end.
- class asr_eval.align.transcription.OuterLoc(mod, pos)[source]¶
A slot that represents a specific position in the ground truth: before/at/after some word index.
See more info about slots in the user guide: Alignments and WER.
- Parameters:
mod (Literal['at', 'pre'])
pos (int)
- class asr_eval.align.transcription.InnerLoc(mod, pos, inner_mod, inner_pos)[source]¶
Bases:
OuterLocA slot that represents a specific inner position in the multivariant ground truth: before/at/after some word index in a multivariant option.
See more info about slots in the user guide: Alignments and WER.
- Parameters:
mod (Literal['at', 'pre'])
pos (int)
inner_mod (Literal['at', 'pre'])
inner_pos (int)
- asr_eval.align.transcription.get_outer_slots(blocks)[source]¶
Enumerates all the outer slots in the ground truth.
See more info about slots in the user guide: Alignments and WER.
- Return type:
Iterator[OuterLoc]- Parameters:
blocks (Sequence[Token | MultiVariantBlock])
- asr_eval.align.transcription.get_outer_slots_values(blocks)[source]¶
Enumerates all the outer slot values in the ground truth.
See more info about slots in the user guide: Alignments and WER.
- Return type:
Iterator[Token|MultiVariantBlock|None]- Parameters:
blocks (Sequence[Token | MultiVariantBlock])
- class asr_eval.align.matching.AlignmentScore(n_word_errors=0, n_correct=0, n_char_errors=0)[source]¶
A joint score that we try to optimize during optimal alignment.
Keeps 3 metrics that we compare lexicographically: compare the first, if equal compare the second, and if also equal compare the third. This ensures that we always find an alignment that is optimal by
n_word_errors, but also may be good by other two metrics. This helps to improve alignments, that is especially important for streaming recognition, because to evaluate latency we need to obtain a good alignment, not only the WER value.- Parameters:
n_word_errors (int)
n_correct (int)
n_char_errors (int)
- n_word_errors: int¶
The total number of word errors (replacements + deletions + insertions).
- n_correct: int¶
The total number of correct matches. Consider the case where “so nothing” matches with “nothing huh”. We can match “so” with “nothing” and “nothing” with “huh” - this gives n_word_errors = 2 that is optimal. Alternatively, we can match “nothing” with “nothing”, and let “so” be deletion and “huh” be insertion. This also gives n_word_errors = 2, but is clearly better.
- n_char_errors: int¶
The sum of character errors in each matches. Note that this is not related CER, because if we match “no thing” with “nothing” we get n_char_errors = 2 + 2 (“no” deletion plus “thing” to “nothing” replacement). This is larger than number of errors in character alignment (which is 1).
- class asr_eval.align.matching.Match(*, true, pred, status, score)[source]¶
A dataclass for a single match between words when aligning a pair of texts.
Note
This is a lower-level object only needed if you work with
solve_optimal_alignment()directly. If you work withAlignment(), matches are automatically converted intoslots, so you don’t operate with them directly.- Parameters:
true (Token | None)
pred (Token | None)
status (Literal['correct', 'deletion', 'insertion', 'replacement'])
score (AlignmentScore)
- status: Literal['correct', 'deletion', 'insertion', 'replacement']¶
One of 4 possible statuses that are standard for the string matching problem:
If “correct” or “replacement”, both tokens are not None. The match is between some token in the ground truth and some token in the prediction, and they are either equal (“correct”) or not equal (“replacement”).
If “deletion”, the pred token is None. This match represents a token existing in the ground truth but not existing in the prediction.
If “insertion”, the true token is None. This match represents a token existing in the prediction but not existing in the ground truth.
- score: AlignmentScore¶
An associated alignment score for the current match.
Roughly, it keeps 0 or 1, depending on whether the words match or not. If the true word is a
Wildcard, then the alignment score is also 0, because wildcard matches with anything.
- class asr_eval.align.matching.MatchesList(matches, total_true_len, score)[source]¶
The result of the optimal alignment algorithm.
- Parameters:
matches (list[Match])
total_true_len (int)
score (AlignmentScore)
- matches: list[Match]¶
A list of matches (correct, replacements, deletions or insertions) that together form an optimal alignment.
- total_true_len: int¶
A total length of the ground truth.
If there are multivariant blocks in the ground truth, only the selected block (the one that matched with the prediction) contributes to the total_true_len.
Also,
Wildcardtokens in the ground truth do not increment the total_true_len. See alsoasr_eval.align.alignment.Alignment.get_true_len().
- score: AlignmentScore¶
A total alignment score. Contains word error counts and some other metrics we try to optimize.
- asr_eval.align.matching.char_edit_distance(true, pred)[source]¶
A
@cachewrapper for nltk.edit_distance. Calculates character edit distance between strings.- Return type:
int- Parameters:
true (str)
pred (str)
- asr_eval.align.char_aligner.char_align(text_1, text_2, placeholder='|', ignore_case=True)[source]¶
A wrapper around biopython to perform character-wise alignment.
This algorithm is currently not included in the main asr_eval workflow, and it does not support multivariant annotation.
The returned dataclass contains 3 strings of equal length, where each position represent a match. The first string represents the first text, the last string represents the second text, and the middle string contains types of maches. For a correct match, the second string contains “|” char. For a replacement, the second string contains “.” char. For deletion or insertion, the second string contains “-” char, and the missing character in the first or the second text is filled with a
placeholder.- Parameters:
text_1 (
str) – The first text to align.text_2 (
str) – The second text to align.placeholder (
str) – A filler for missing (non-matched) characters.ignore_case (
bool) – If True, aligns ignoring case. The output texts still contain the original case.
- Return type:
Example
>>> al = char_align( ... 'Set an alarm for 7 am', ... 'SET A ALARM FOR SEVEN A.M.' ... ) >>> print(al.first + '\n' + al.matching + '\n' + al.second) Set an alarm for 7|||| a|m| |||||-|||||||||||.----||-|- SET A| ALARM FOR SEVEN A.M.
- class asr_eval.align.char_aligner.CharAligned(first, matching, second)[source]¶
A char-level alignment for two texts, obtained by
char_align()(see its dostring for details).- Parameters:
first (str)
matching (str)
second (str)
- asr_eval.align.char_aligner.get_spans_for_char_aligned(al)[source]¶
Locates positions in the
CharAlignedwhere both texts contain space. Splits by these positions, and returns the resulting spans.This can be useful to match predictions from two models, where there may be cases when a single word from one first model matches with two words from another model. In this case the current function will return an interval spanning both words.
- Return type:
list[tuple[int,int]]- Parameters:
al (CharAligned)
- class asr_eval.align.metrics.Metrics(true_len=0, n_replacements=0, n_insertions=0, n_deletions=0)[source]¶
A dataclass container for error counters to calculate WER (word error rate).
To obtain WER value, run
word_error_rate(). See examples in theAlignment()docstrings and the user guide Alignments and WER.- Parameters:
true_len (int)
n_replacements (int)
n_insertions (int)
n_deletions (int)
- property n_errors: int¶
The total number of word errors (replacements + insertions + deletions).
- word_error_rate(clip=False)[source]¶
The WER (word error rate) value.
If true_len == 0, replaces it with 1.
- Parameters:
clip (
bool) – If True, the value will be clipped between 0 and 1. This helps to stabilize metric, otherwise long insertions may lead to a gigantic WER value on a single sample, that affects the whole dataset metric and depends on the generation limit. See also the related parametermax_consecutive_insertionsinerror_listing(), that has similar semantics but is more flexible.- Return type:
float
- asr_eval.align.metrics.average_wer(samples, mode)[source]¶
Averages WER value for a list of samples.
Two alternative averaging methods are implemented:
1. In “plain” method we calculate WER for each sample, clipping it from 0 to 1, and then average all the values. 2. In “concat” method we sum up each counter (replacements, deletions, insertions and ground truth lengths) for all samples, and then calculate the WER value from the resulting counters. This is roughly equivalent to concatenating all the predictions and ground truth before calculating WER. Also, if ground truth length > 0 for all samples, this is equal to averaging WER (with
clip=False) for all samples, taking their ground truth lengths as averaging weights.Thus, in “concat” method long samples have larger effect on the overall metric, which is reasonable. The “plain” mode is also reasonable, because different samples may represent different conditions (acoustical, lexical etc.) and can be viewed as many different classes (or clusters), and “plain” mode is similar to macro-averaging metrics for these classes.
- Return type:
float- Parameters:
samples (list[Metrics])
mode (Literal['plain', 'concat'])
- asr_eval.align.metrics.bootstrap(samples, calc_metric, rounds=100, random_seed=0)[source]¶
Calculates a metric uncertainty via bootstrapping.
Given a list of samples and a function
calc_metricthat calcualtes averaged metric, run the functionroundstimes, each time selecting N from N samples with replacement, with the given random_seed. Returns the results in thebootstrap_valuesfield.Also applies the
calc_metricto the wholesampleslist without subsampling and returns the result in themain_valuefield.- Return type:
MetricDistribution
- Parameters:
samples (T)
calc_metric (Callable[[T], float])
rounds (int)
random_seed (int | None)
Example
>>> import numpy as np >>> from asr_eval.align.metrics import bootstrap >>> outcomes = np.random.default_rng(0).integers(0, 2, size=100) >>> distribution = bootstrap(outcomes, np.mean) >>> distribution.quantiles((0.1, 0.9)) [0.509, 0.6310000000000001] >>> distribution.main_value 0.56
- class asr_eval.align.metrics.MetricDistribution(main_value, bootstrap_values)[source]¶
The result of a
bootstrap()algorithm.- Parameters:
main_value (float)
bootstrap_values (list[float])
- main_value: float¶
Metric value calculated on the whole dataset.
- bootstrap_values: list[float]¶
Metric values on bootstrap subsets.
- class asr_eval.align.metrics.DatasetMetric(wer, n_replacements, n_insertions, n_deletions)[source]¶
Keeps a bootstrap distribution for WER, number of replacements, insertions and deletions.
This helps to determine confidence intervals.
- Parameters:
wer (MetricDistribution)
n_replacements (MetricDistribution)
n_insertions (MetricDistribution)
n_deletions (MetricDistribution)
- asr_eval.align.metrics.dataset_metric_to_dataframe(metrics, what='wer', quantile_1=0.1, quantile_2=0.9)[source]¶
Given bootstrap distributions for several models, summarizes them into a table.
A helper function for a dashboard.
- Return type:
DataFrame- Parameters:
metrics (dict[str, DatasetMetric])
what (Literal['wer', 'n_replacements', 'n_insertions', 'n_deletions'])
quantile_1 (float)
quantile_2 (float)
- asr_eval.align.metrics.plot_dataset_metric(metrics, what='wer', show=True, quantile_1=0.1, quantile_2=0.9)[source]¶
Given bootstrap distributions for several models, summarizes them into a plot.
A helper function for a dashboard.
If
show=True, callsplt.show()afterwards. Returns base64-encoded image.- Return type:
str- Parameters:
metrics (dict[str, DatasetMetric])
what (Literal['wer', 'n_replacements', 'n_insertions', 'n_deletions'])
show (bool)
quantile_1 (float)
quantile_2 (float)
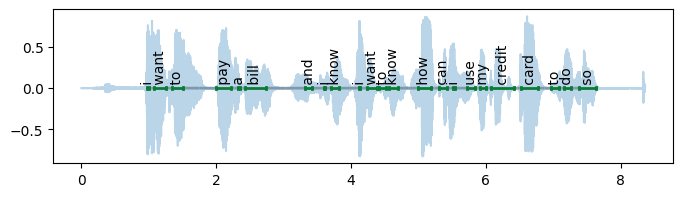
- asr_eval.align.plots.draw_timed_transcription(transcription, y_pos=0, y_delta=-1, y_tick_width=0.1, ax=None, graybox_y=None)[source]¶
An utility to draw a transcription, possibly multivariant, with filled timings (see the full example in
fill_word_timings_inplace()).Used in streaming evaluation diagrams.
- Parameters:
transcription (Transcription)
y_pos (float)
y_delta (float)
y_tick_width (float)
ax (Axes | None)
graybox_y (tuple[float, float] | None)
- asr_eval.align.timings.fill_word_timings_inplace(model, waveform, transcription, verbose=False)[source]¶
Fills
start_timeandend_timein transcription via forced alignment.- Parameters:
model (
CTC) – A model withCTCinterface. Normally it should support all the characters found in transcription ignoring case. However, if it does not support some options in a multivariant block, the function will run some propagation rules and try to fill the timings. For example, if there is no digits in the model’s vocab, it will still able to fill the timings for a block{1|one}. We first fill the timings for the word “one”, then mirror them to the word “1”.waveform (
ndarray[tuple[int,...],dtype[floating[Any]]]) – The audio 16000 Hz, possibly long. For long audios will wrap the CTC model into aLongformCTCthat works via logit averaging of uniform chunks with overlap.transcription (
Transcription) – A single-variant or multivariant transcription.verbose (
bool) – Enable debug output.
- Raises:
CannotFillTimings – if cannot fill timings due to the absence of the required characters in the model’s vocab, or other limitations of the algorithm.
Example
>>> from typing import cast >>> from datasets import load_dataset, Audio >>> from asr_eval.align.timings import fill_word_timings_inplace >>> from asr_eval.bench.datasets import get_dataset >>> from asr_eval.align.parsing import DEFAULT_PARSER >>> from asr_eval.align.plots import draw_timed_transcription >>> dataset = ( ... load_dataset('PolyAI/minds14', name='en-GB', split='train') ... .cast_column('audio', Audio(16_000)) ... ) >>> sample = dataset[0] >>> transcription = DEFAULT_PARSER \ ... .parse_transcription(sample['transcription']) >>> waveform = sample['audio']['array']
>>> # # to display the audio: >>> # import IPython.display >>> # IPython.display.Audio(waveform, rate=16_000)
>>> # For English: >>> from asr_eval.models.wav2vec2_wrapper import Wav2vec2Wrapper >>> model = Wav2vec2Wrapper('facebook/wav2vec2-base-960h')
>>> # # For Russian: >>> # from asr_eval.models.gigaam_wrapper import GigaAMShortformCTC >>> # model = GigaAMShortformCTC('v2')
>>> fill_word_timings_inplace(model, waveform, transcription) >>> print(transcription.blocks[:6]) (Token(i, t=(1.0, 1.0)), Token(want, t=(1.1, 1.3)), Token(to, t=(1.3, 1.5)), Token(pay, t=(2.0, 2.2)), Token(a, t=(2.3, 2.4)), Token(bill, t=(2.4, 2.7)))
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> plt.figure(figsize=(8, 2)) <...> >>> draw_timed_transcription(transcription, y_tick_width=0.02) >>> plt.plot(np.arange(len(waveform)) / 16000, waveform, alpha=0.3) [...]
- exception asr_eval.align.timings.CannotFillTimings[source]¶
Bases:
ValueErrorAn exception raised from
fill_word_timings_inplace()that indicates a failure to fill timings, usually because of absence of the required characters in the model vocab.
asr_eval.align.solvers¶
- asr_eval.align.solvers.dynprog.solve_optimal_alignment(true, pred)[source]¶
Solves an optimal alignment task via dynamic programming. Uses a generalized version of the Needleman-Wunsch algorithm with the following modifications:
Support for multivariant blocks in both texts.
Support for
Wildcardsymbols in both texts.Better alignment due to the optimization of additional metrics (see the
AlignmentScorefor details).
The second returned value contains a selected option index for each multivariant block in true.
Note
In the asr_eval workflow pred is single-variant. However, the algorithm supports multivariant blocks and
Wildcardsymbols for both true and pred.Example
>>> from asr_eval.align.parsing import DEFAULT_PARSER >>> from asr_eval.align.solvers.dynprog import solve_optimal_alignment >>> true = 'hey <*> {eh} {one|1} {dollar|$}' >>> pred = 'Hey man eh dollar' >>> matches_list, selected_blocks = solve_optimal_alignment( ... DEFAULT_PARSER.parse_transcription(true), ... DEFAULT_PARSER.parse_transcription(pred), ... ) >>> matches_list.score AlignmentScore(n_word_errors=1, n_correct=3, n_char_errors=1) >>> # selected #0 in {eh|}, #1 in {one|1}, #0 in {dollar|$} >>> selected_blocks [0, 1, 0]
- Return type:
tuple[MatchesList,list[int]]- Parameters:
true (Transcription)
pred (Transcription)
- asr_eval.align.solvers.recursive.solve_optimal_alignment(true, pred, determine_selected_multivariant_indices=True)[source]¶
Solves an optimal alignment task via recursion. Supports multivariant annotations with
Wildcardinsertions.Note
This method is legacy, consired using
asr_eval.align.solvers.dynprog.solve_optimal_alignment()instead.The last returned value is a selected option index for each multivariant block, if present in the ground truth.
- Return type:
tuple[MatchesList,list[int]]- Parameters:
true (Transcription)
pred (SingleVariantTranscription)
determine_selected_multivariant_indices (bool)