Datasets list¶
This page describes a list of datasets registered in asr_eval and available
via get_dataset function. In general, every audio dataset in Hugging Face
format can be used in asr_eval, but registered datasets can be referred via unique
names and have a standardized format (see the “Research framework” page).
For now, in early development, we focused mainly on Russian datasets, but we plan to extend our collection to other languages as well.
Adding datasets
You can add new datasets locally, as described in Framework quickstart. You also can suggest new datasets by opening an issue or pull request.
Note about splits
Since asr_eval is used primarily for testing, we ensure that all the datasets have “test” split. Some datasets on Hugging Face are not split and have a single “train” split; in this case, we refer to it as “test” in asr_eval.
Audioset Nonspeech¶
A processed version of the AudioSet dataset with non-speech audio recordings. The dataset was filtered to exclude examples with speech. In asr_eval we added the empty “transcription” column, which was not present in the dataset on Hugging Face, to evaluate false positive detections in ASR.
However, it turned out that roughly 20% of the examples do contain speech on different languages, sometimes in the form of vocals. Also, there are examples with laughter and other vocalizations. Music appears frequently in the samples. Thus, samples may be ambiguous to transcribe - for example, “ha-ha” and “music plays” can be considered valid transcriptions. This complicates model evaluation; we recommend to inspect the predictions manually, in addition to WER metrics.
Name |
audioset-nonspeech |
|---|---|
Splits |
test - 3513 samples, 9.65 hours (after removing 4 duplicates)
train - 9416 samples, 25.87 hours (after removing 2 duplicates)
validation - 1058 samples, 2.91 hours (after removing 1 duplicate)
|
Source |
|
Lengths |
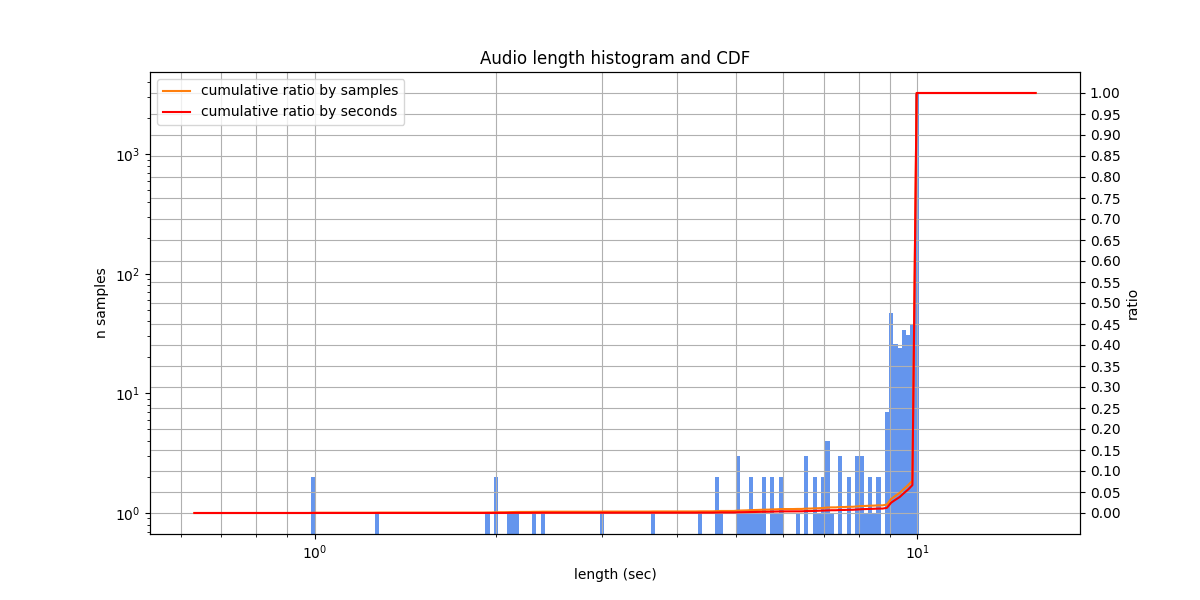
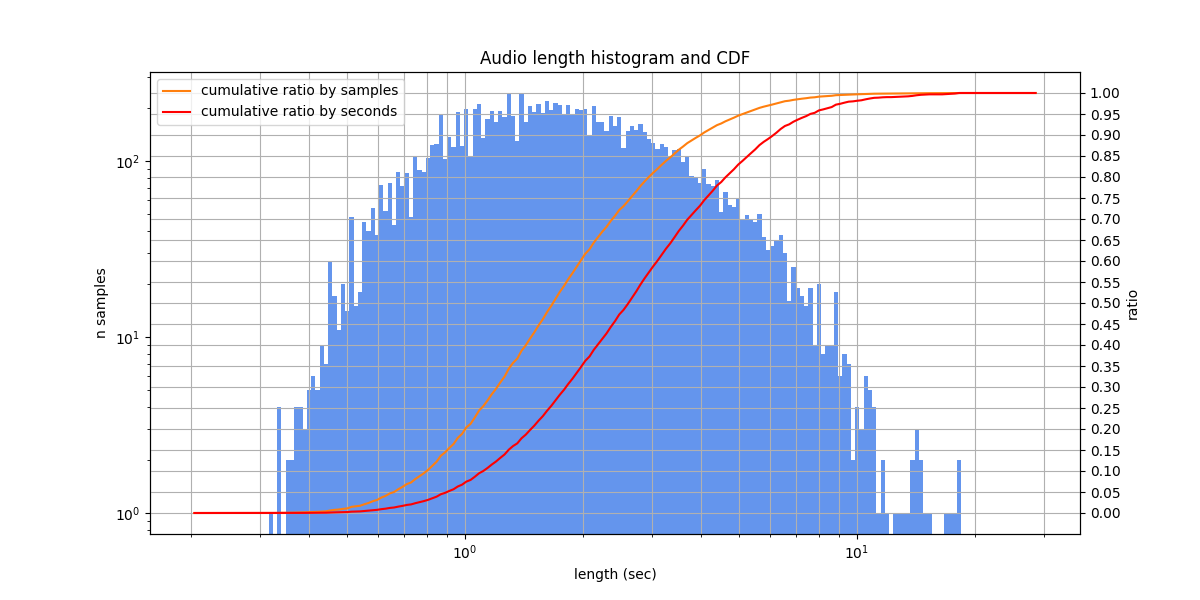
Audio lengths from 1.0 s to 10.0 s, typically from 10.0 s to 10.0 s
|
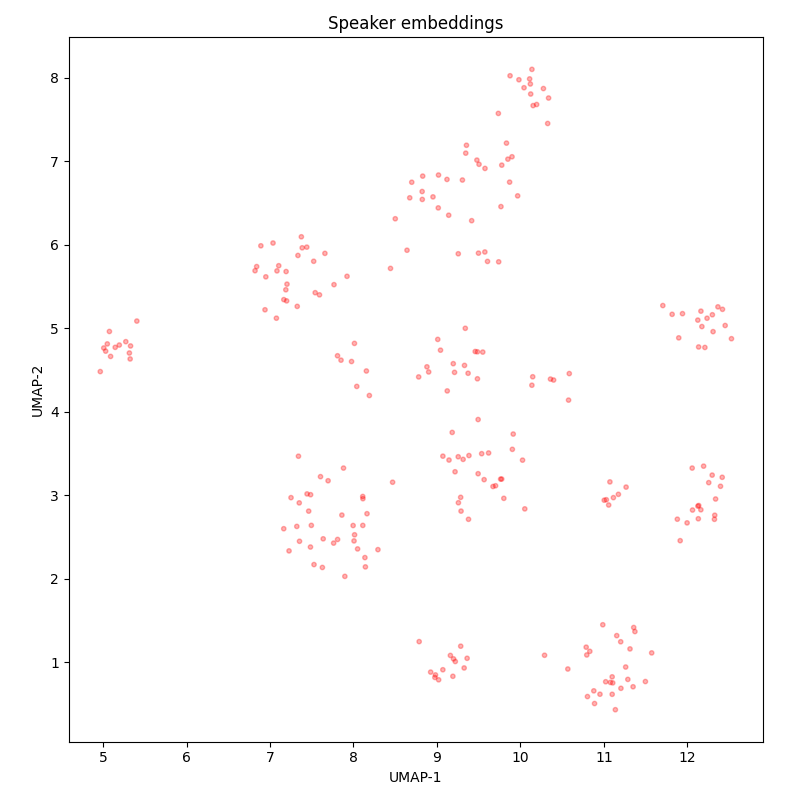
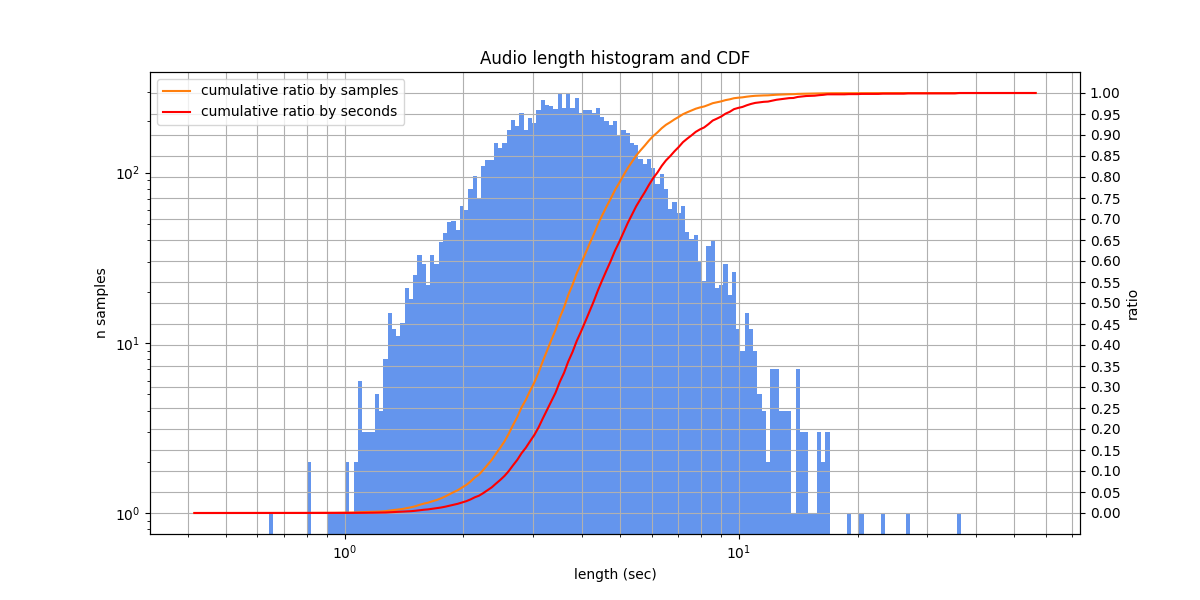
Fleurs (ru_ru)¶
The speech version of the FLoRes machine translation benchmark. Contains n-way parallel sentences from the FLoRes dev and devtest publicly available sets, in 102 languages (here we use only the Russian subset).
The speakers read aloud Wikipedia-style texts, at a medium or slow pace, without disfluencies or noises. In the labeling, numbers are usually written as numerals. Due to the nature of the texts, they often contain rare proper names. There are very rare mislabelings (which are actually a reader’s mistakes) and illiterate spellings of words.
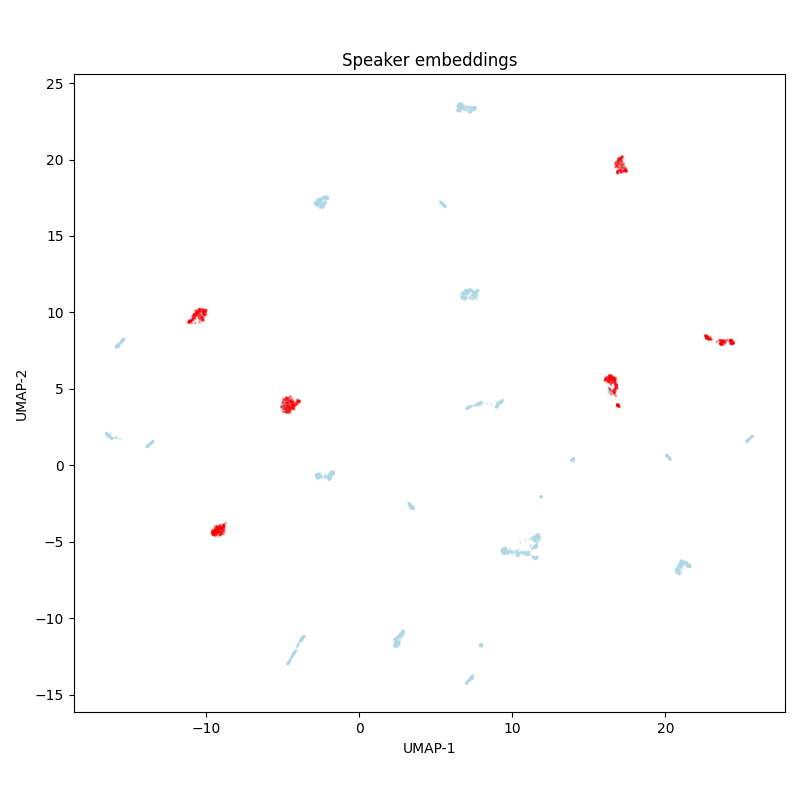
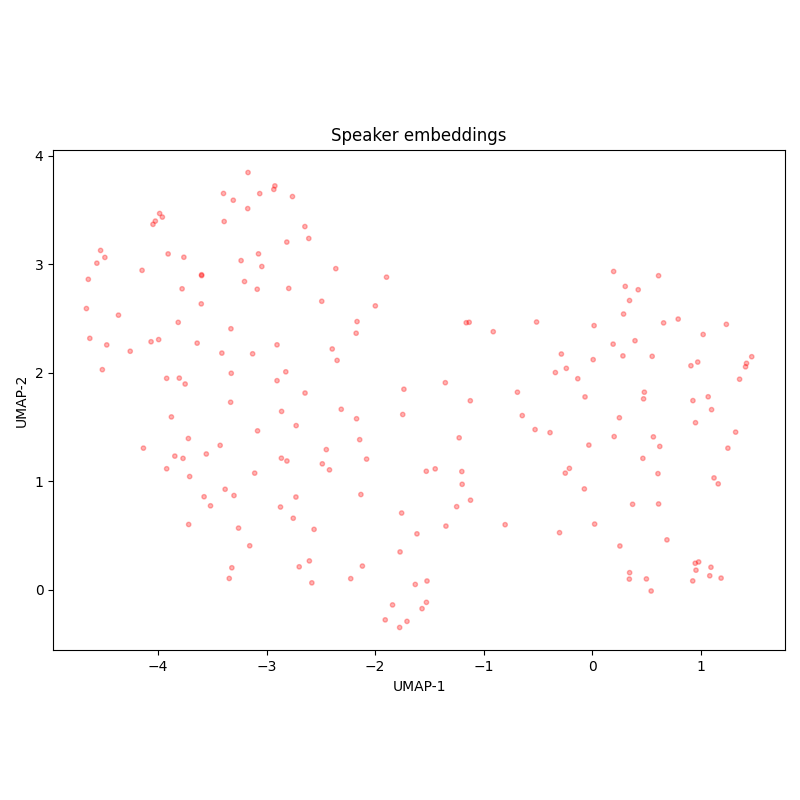
The diversity of speakers is low: according to speaker embedding UMAP-projections, there are only 6 speakers in the test set, which are also present in the training set.
Name |
fleurs-ru |
|---|---|
Splits |
test - 775 samples, 2.50 hours
train - 2562 samples, 8.05 hours
validation - 356 samples, 1.08 hours
|
Source |
|
Language |
Russian |
Lengths |
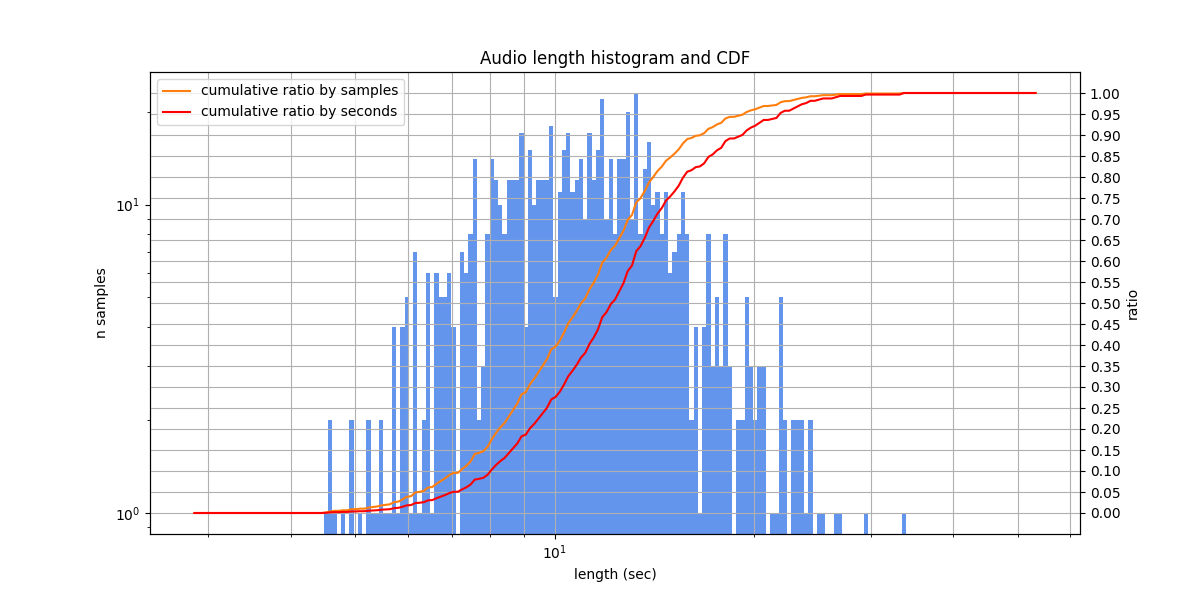
Audio lengths from 4.5 s to 33.8 s, typically from 8.3 s to 14.2 s
|
Speakers |
Golos farfield¶
Russian speech, prepared by SberDevices Team. The speakers talk with virtual assistants and usually call them by names: Sber, Afina, and Joy. The phrases are sometimes typical - like “Афина, завершить сценарий!” (“Afina, finish the script!”), and sometimes represent diverse questions or requests. Speakers are clearly aware that they are speaking to a speech recognition system: they speak clearly enough, without filler words and disfluencies. Some samples are very quiet - maybe recorded as is, or wrongly normalized. In transcriptions numbers are always written in words.
In test set the diversity of speakers is moderate: around 16 speakers. Train and test sets are not random splits: in train, the diversity of speakers is much higher.
Name |
golos-farfield |
|---|---|
Splits |
test - 1916 samples, 1.41 hours
train - 9570 samples, 10.29 hours
validation - 933 samples, 1.02 hours
|
Source |
https://huggingface.co/datasets/bond005/sberdevices_golos_100h_farfield |
Language |
Russian |
Lengths |
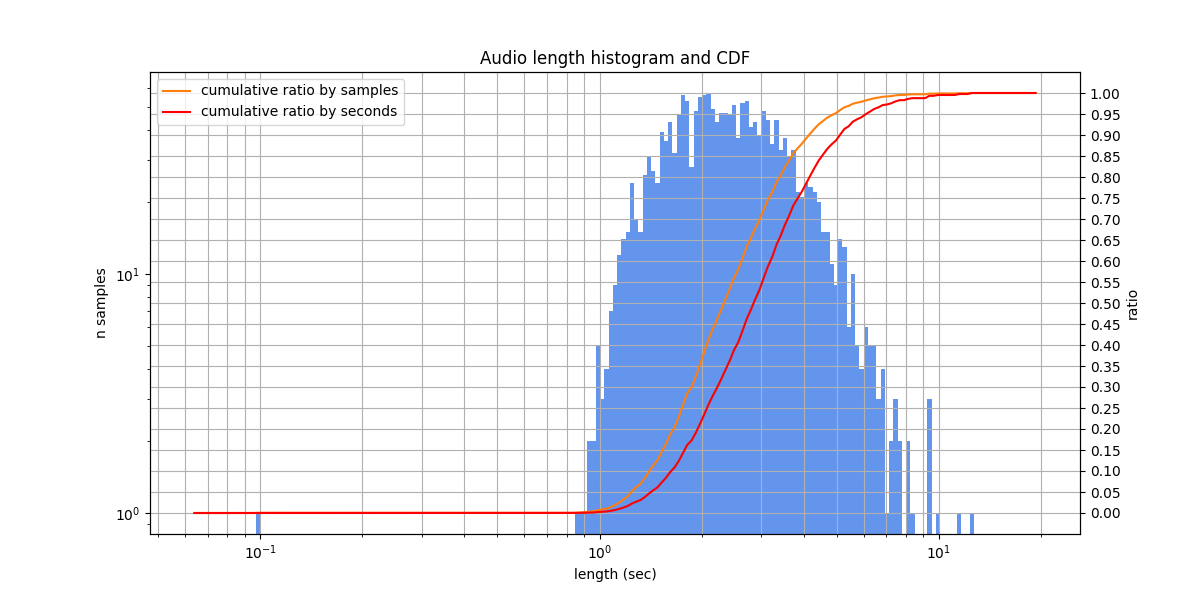
Audio lengths from 0.1 s to 12.3 s, typically from 1.7 s to 3.4 s
|
Speakers |
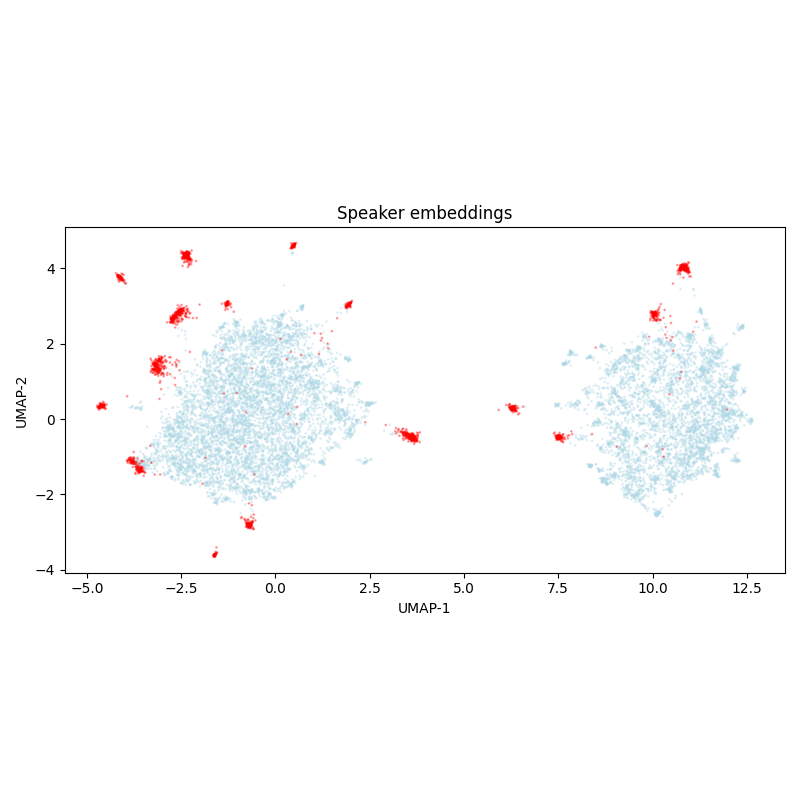
We also provide a small version with multivariant relabeling. The relabeling was manual from scratch, without looking at the original or machine transcriptions. Due to the dataset properties, it is not very different from the original version: 37 of 250 samples contain multivariant blocks.
In addition, we provide a golos-farfield-single-variant dataset, that is a subset of golos-farfield with samples included in golos-farfield-multivariant, to enable direct side by side comparision.
Name |
golos-farfield-multivariant |
|---|---|
Splits |
test - 250 samples, 0.19 hours
|
Source |
asr_eval/_data/relabelings/golos-farfield.txt |
Language |
Russian |
Lengths |
Audio lengths from 0.9 s to 9.5 s, typically from 1.7 s to 3.6 s
|
Speakers |
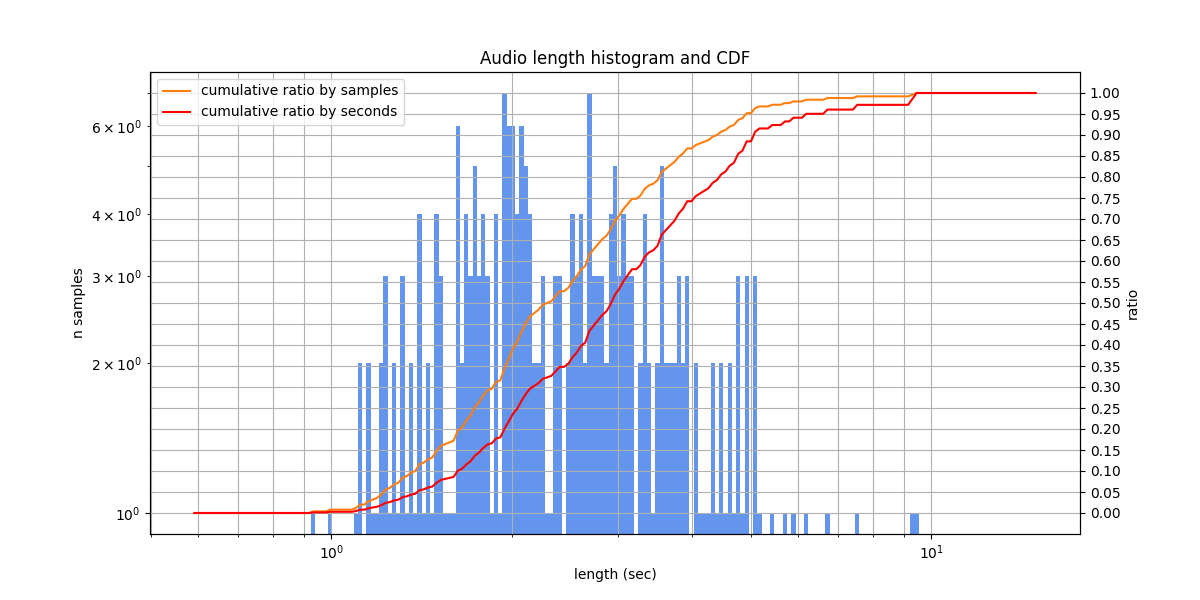
Golos crowd¶
Russian speech from farfield domain (communication with smart devices), prepared by SberDevices Team. The calls of virtual assistants, often pronounced, are Alisa, Afina, Sber, Salut, Joy. The phrases are questions and requests (less typical commands compared to Golos farfield). As in Golos farfield, some samples are very quiet, and numbers are written in words. Acoustlc conditions are similar to that of Golos farfield, but noisy samples are slighly more common. Despite the name, background speech is very rare.
The diversity of speakers is high: in the speaker embedding UMAP-projections the majority of voices do not form clusters.
Name |
golos-crowd |
|---|---|
Splits |
test - 9990 samples, 11.20 hours (after removing 4 duplicates)
train - 7992 samples, 8.95 hours (after removing 1 duplicate)
validation - 793 samples, 0.90 hours
|
Source |
https://huggingface.co/datasets/bond005/sberdevices_golos_10h_crowd |
Language |
Russian |
Lengths |
Audio lengths from 0.6 s to 36.2 s, typically from 2.7 s to 5.1 s
|
Speakers |
Multivariant Ru¶
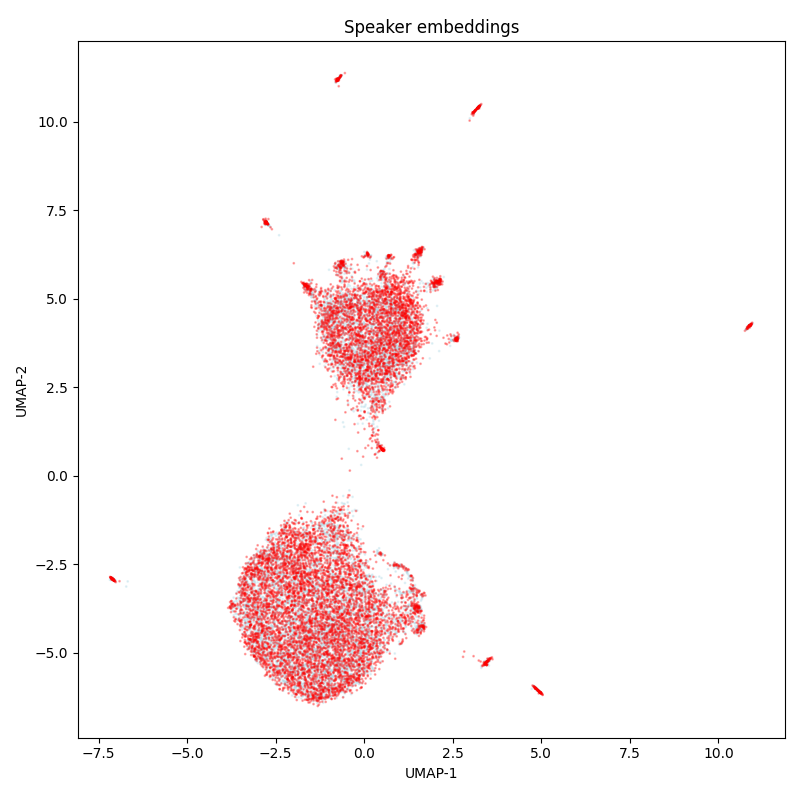
A dataset collected from YODAS YouTube recordings with multivariant labeling. Roughly 50% of the samples look like a narrator reading from a paper. Other examples are free narration or commentary on real-time events. The diversity of speakers is high: speakers are almost never repeated in different samples.
An important feature of the dataset is the audio length around 2 minutes. This helps to evaluate a longform transcription.
The labeling was prepared in several stages. On stage 1, the Whisper model generated transcriptions to start with. On stage 2, two human labelers performed a correction. On stage 3, a human labeler performed a correction again, this time seeing aligned transcriptions of about 15 models and the discrepancies between them and the current labeling. This helps to mitigate cases when a human labeler stops at one correct option and doesn’t think about the fact that there are other correct options to transcribe (speech recognition models often highlight them).
Theoretically, this data could overlap with web-scale training sets for speech recognition models.
Name |
multivariant-v2 |
|---|---|
Splits |
test - 92 samples, 3.38 hours
|
Source |
stored locally, to be released |
Language |
Russian |
Lengths |
Audio lengths from 94.7 s to 140.0 s, typically from 129.1 s to 139.6 s
|
Speakers |
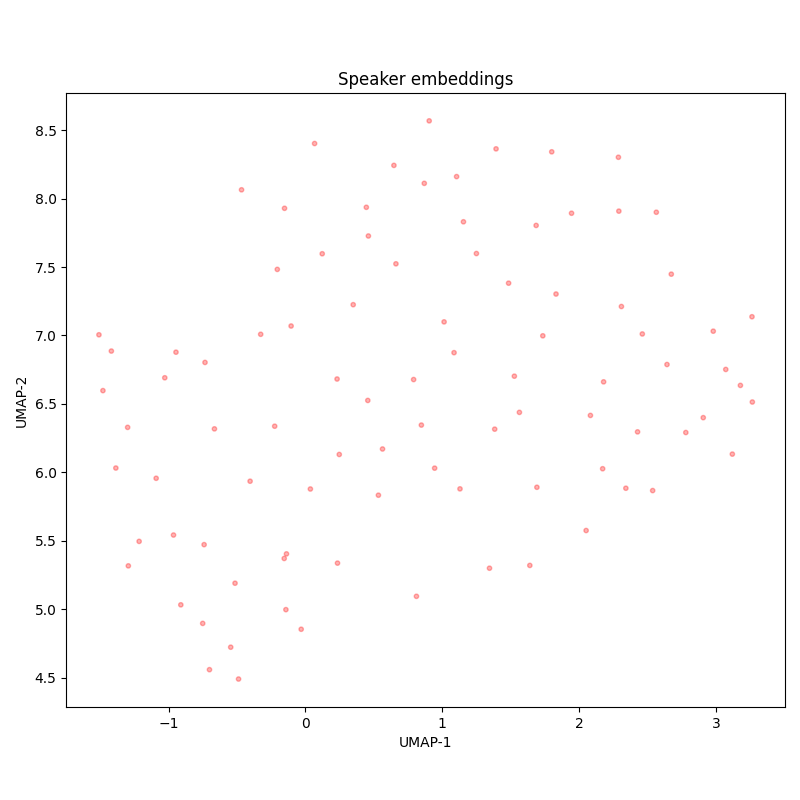
A larger version of multivariant-v2 with less carefully checked labeling: the stage 3 was omitted, and the stage 2 was performed by only a single labeler.
Name |
multivariant-v1-200 |
|---|---|
Splits |
test - 200 samples, 7.31 hours
|
Source |
stored locally, to be released |
Language |
Russian |
Lengths |
Audio lengths from 71.8 s to 140.0 s, typically from 127.1 s to 139.4 s
|
Speakers |
OpenSTT subsets¶
We took 3 Russian OpenSTT subsets with human labeling. Preparing:
# a default cache dir is ~/.cache/asr_eval/datasets
# you can set a custom $ASR_EVAL_CACHE and pass it as env variable into Python
ASR_EVAL_CACHE=~/.cache/asr_eval/datasets
mkdir -p $ASR_EVAL_CACHE/datasets/openstt
cd $ASR_EVAL_CACHE/datasets/openstt
wget https://azureopendatastorage.blob.core.windows.net/openstt/ru_open_stt_opus/archives/asr_calls_2_val.tar.gz
wget https://azureopendatastorage.blob.core.windows.net/openstt/ru_open_stt_opus/archives/buriy_audiobooks_2_val.tar.gz
wget https://azureopendatastorage.blob.core.windows.net/openstt/ru_open_stt_opus/archives/public_youtube700_val.tar.gz
tar -xvzf asr_calls_2_val.tar.gz && rm asr_calls_2_val.tar.gz
tar -xvzf buriy_audiobooks_2_val.tar.gz && rm buriy_audiobooks_2_val.tar.gz
tar -xvzf public_youtube700_val.tar.gz && rm public_youtube700_val.tar.gz
The asr-calls-2-val dataset of Russian phone calls with human labeling. The dataset consists of prank phone calls cut into small fragments a few seconds long. In the labeling, numbers are written as words. The labeling is very verbose: it contain even vocalization fillers like “umm” and disfluencies in the form of partially pronounced words, that are not typically transcribed by models. Around 10-20% of samples contain labeling errors.
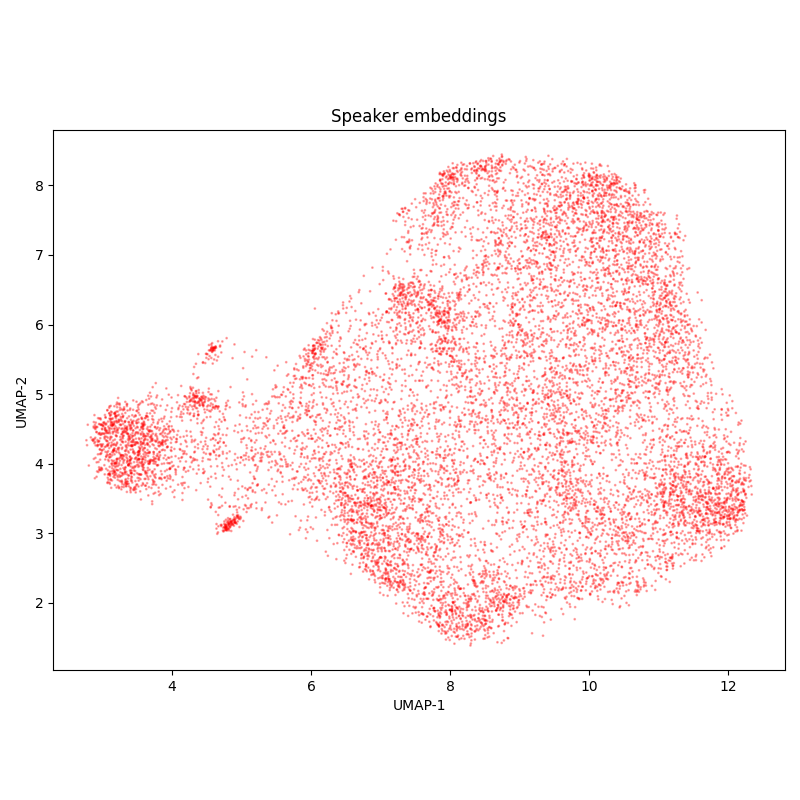
The speaker embedding UMAP-projections shows blurred clusters. It’s likely that each cluster belongs to one speaker, and they are blurred due to the audio noise. In this case, a large proportion of samples relate to just a few speakers, what is expected based on the data source.
Theoretically, this data could overlap with web-scale training sets for speech recognition models.
Name |
openstt-asr-calls-2-val |
|---|---|
Splits |
test - 12844 samples, 7.67 hours (after removing 106 duplicates)
|
Source |
|
Language |
Russian |
Lengths |
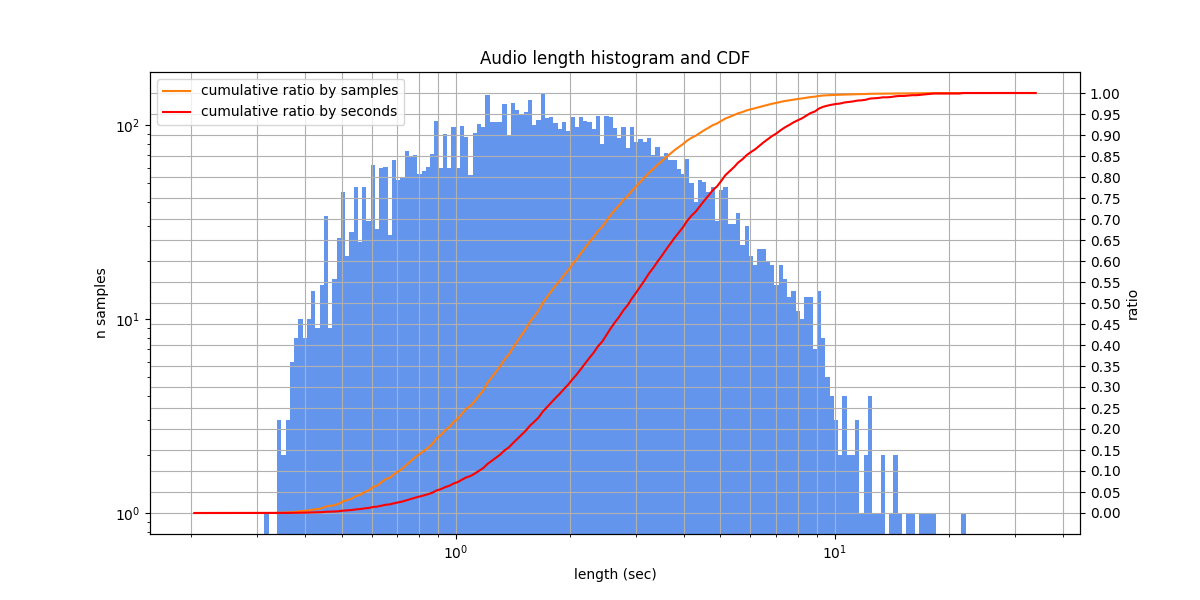
Audio lengths from 0.3 s to 18.3 s, typically from 1.0 s to 3.0 s
|
Speakers |
The buriy-audiobooks-2-val dataset of audiobooks with human labeling. The acoustic conditions, tempo and clarity of speech are fine, which is typical for audiobooks domain. The labeling overall is not bad, but there are some spelling errors and occasionally inaccurate audio cutting. There is a problem with hyphenated words that are merged and the hyphen is removed.
The diversity of speakers is moderate: around 50 speakers, a few dozen or hundreds of samples per speaker. However, we didn’t check if speakers, and, more importantly, books overlap between this set and train sets from OpenSTT, and other web-scale training sets for speech recognition models.
Name |
openstt-buriy-audiobooks-2-val |
|---|---|
Splits |
test - 7850 samples, 4.90 hours
|
Source |
|
Language |
Russian |
Lengths |
Audio lengths from 0.3 s to 21.7 s, typically from 1.0 s to 3.2 s
|
Speakers |
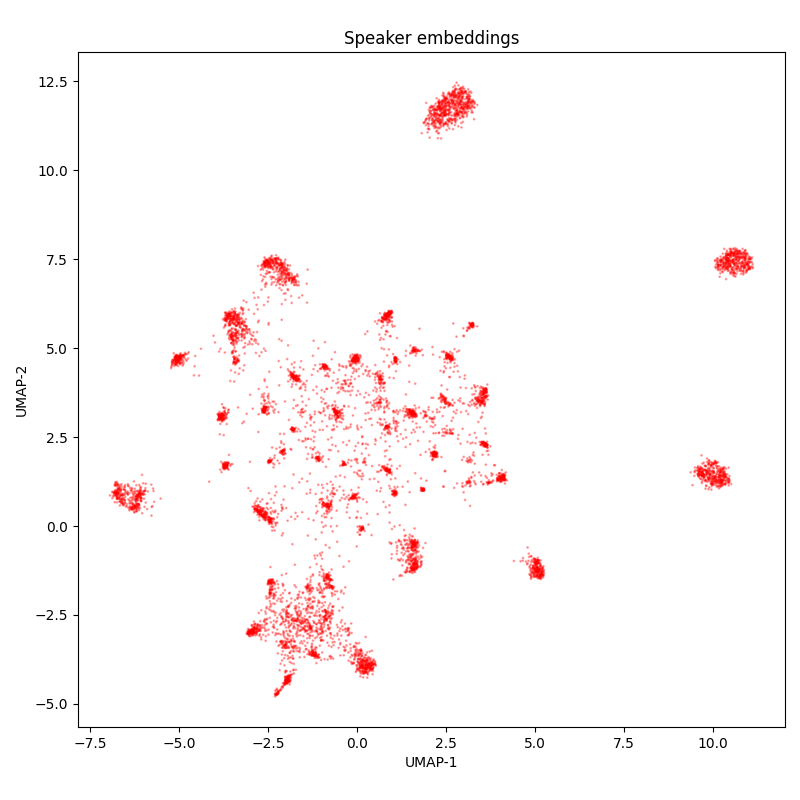
The public-youtube700-val dataset sourced from YouTube with human labeling. The acoustics and vocabulary are diverse. The labeling quality is not bad. As in the asr-calls-2-val dataset, the labeling is very verbose: it contain even vocalization fillers. As in the buriy-audiobooks-2-val dataset, hyphenated words are merged and hyphen is removed. Occasionally there is inaccurate audio cutting.
The diversity of speakers is moderate: around 30 speakers. However, we didn’t check if speakers, and, more importantly, the videos overlap between this set and train sets from OpenSTT, and other web-scale training sets for speech recognition models.
Name |
openstt-public-youtube700-val |
|---|---|
Splits |
test - 7311 samples, 4.46 hours
|
Source |
|
Language |
Russian |
Lengths |
Audio lengths from 0.3 s to 13.1 s, typically from 1.1 s to 3.2 s
|
Speakers |
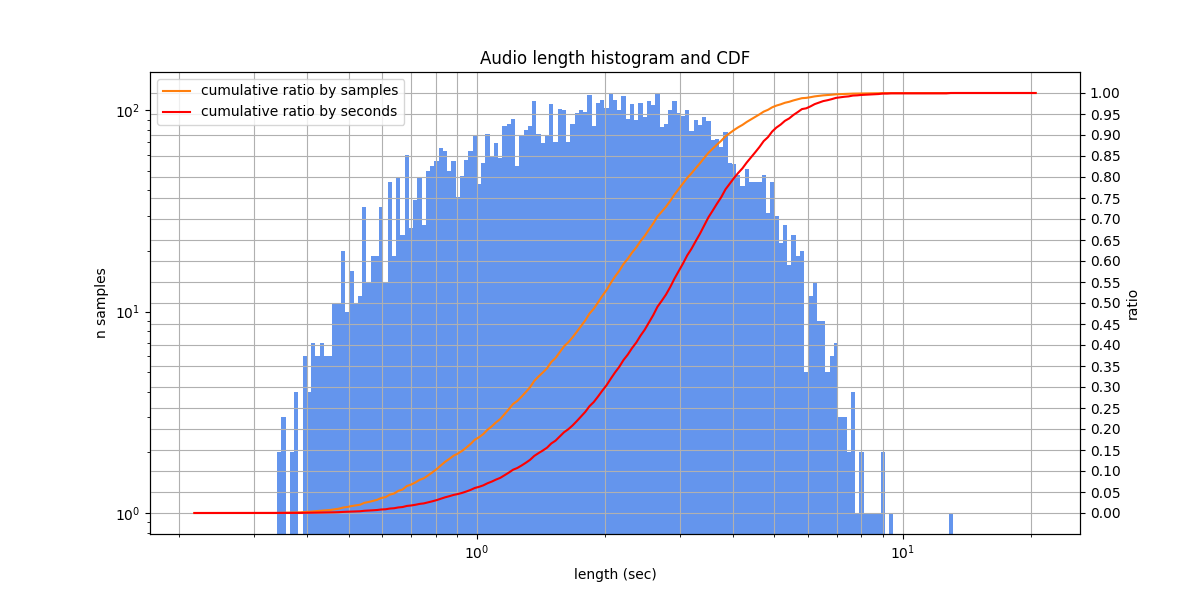
Podlodka¶
A dataset collected from Russian Podlodka podcast with human labeling.
There are few clusters in the UMAP-projected speaker embeddings, indiacating the same speaker in different audios (possibly, either podcast host, or the same guest). We didn’t check whether there is a situation where the same podcast is present in both train and test sets. The labeling is overall fine, but in evaluation there may be problems with numerals, filler words, and numerous terms that can be written in English or Russian.
Name |
podlodka |
|---|---|
Splits |
test - 20 samples, 0.14 hours
train - 67 samples, 0.42 hours
(validation and test sets turn out to be identical; to prevent possible
overfitting the test set, we omitted the validation set)
|
Source |
|
Language |
Russian |
Lengths |
Audio lengths from 8.1 s to 59.4 s, typically from 15.7 s to 27.6 s
|
Since the Podlodka dataset is too small, we merged its train and test sets into a single dataset called podlodka-full. It is suitable to evaluate models which were not trained on the Podlodka train set.
Name |
podlodka-full |
|---|---|
Splits |
test - 87 samples, 0.55 hours
|
Source |
https://huggingface.co/datasets/bond005/podlodka_speech (merged splits) |
Language |
Russian |
Lengths |
Audio lengths from 6.1 s to 59.4 s, typically from 12.1 s to 30.7 s
|
Speakers |
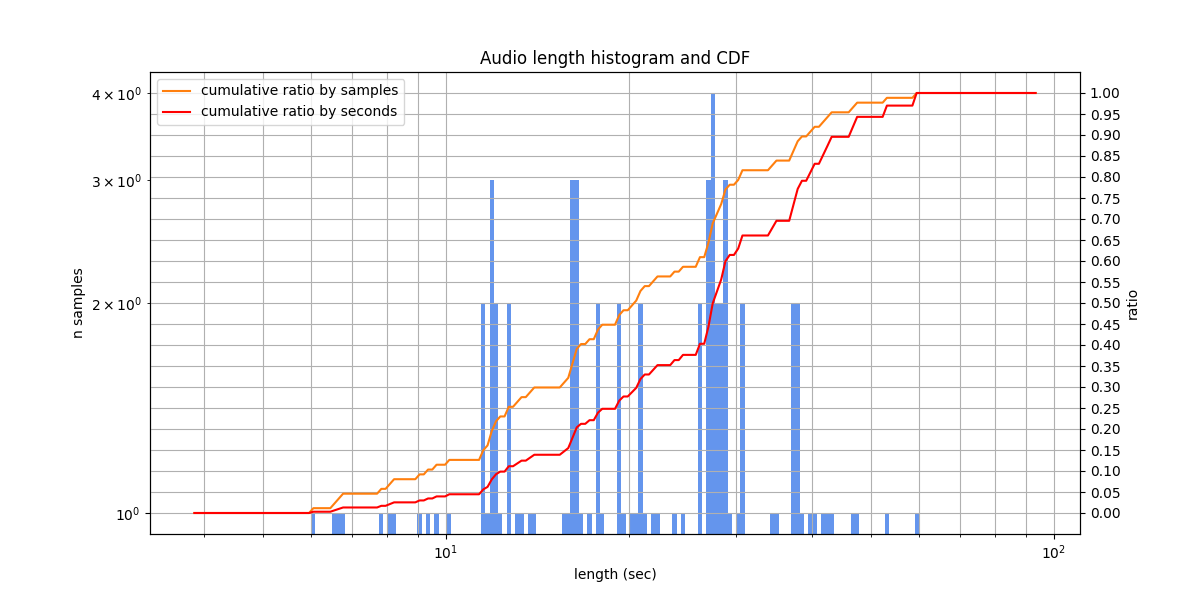
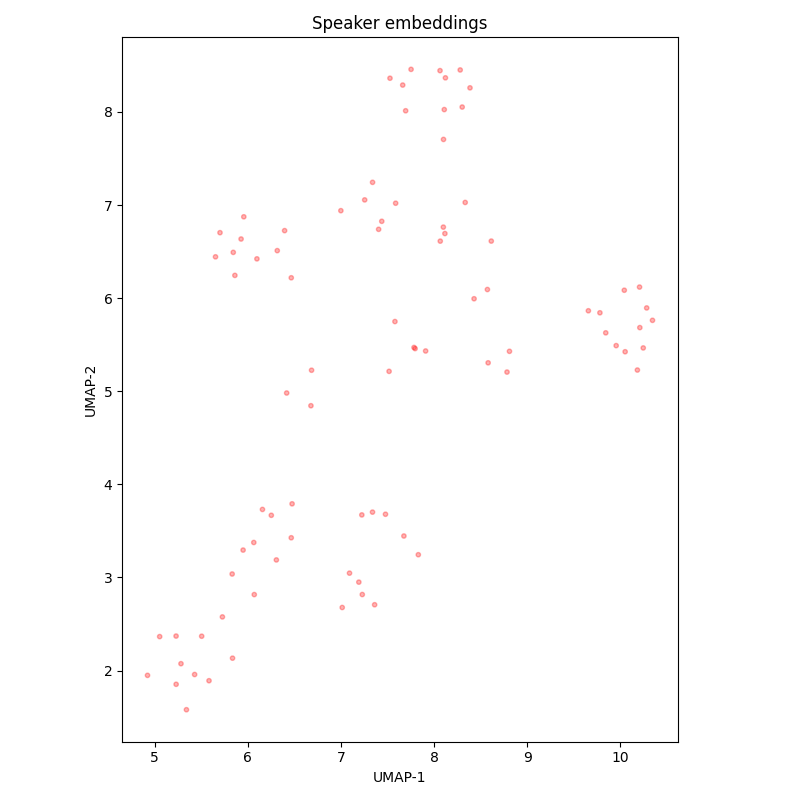
RuLibrispeech¶
A Russian audiobooks dataset. The test set seem to contain only Pushkin’s tales, while the train set contains literature written by another authors. It follows that both sets are similar in acoustic conditions, but may differ lexically: for example, Pushkin’s tales from the test set contain many old Russian word forms. However, these tales, for being popular, could be included in web-scale training sets for speech recognition models.
The diversity of speakers is low: only 7 speakers in the test set, however, they do not overlap with the train set.
Name |
rulibrispeech |
|---|---|
Splits |
test - 1352 samples, 2.65 hours
train - 54472 samples, 92.79 hours
validation - 1400 samples, 2.81 hours
|
Source |
|
Language |
Russian |
Lengths |
Audio lengths from 1.9 s to 19.9 s, typically from 4.0 s to 9.6 s
|
Speakers |
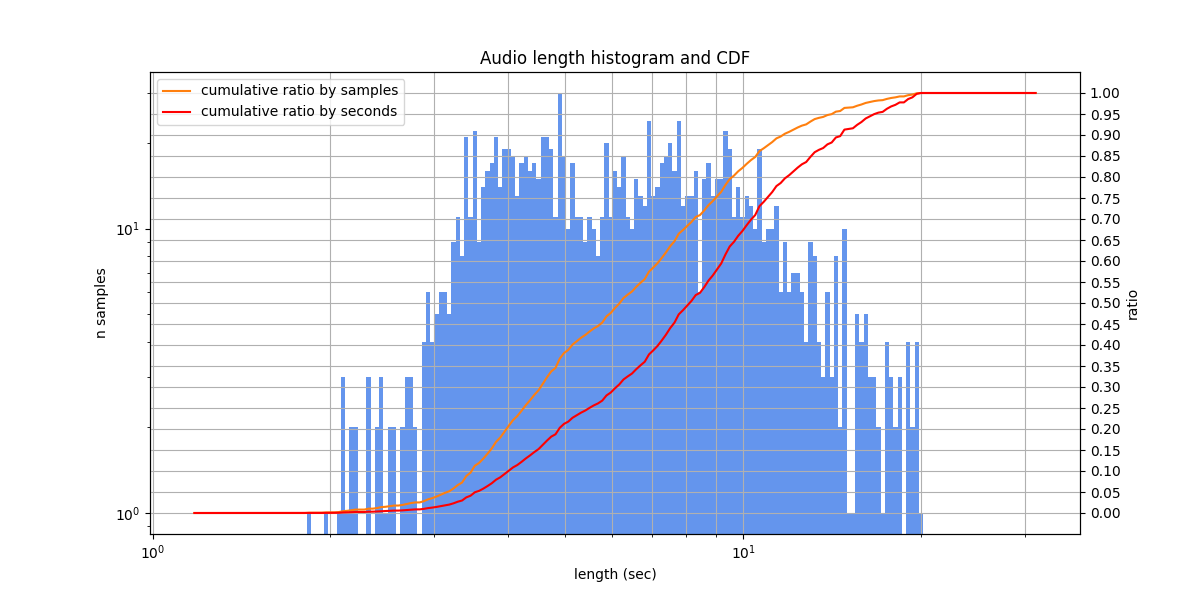
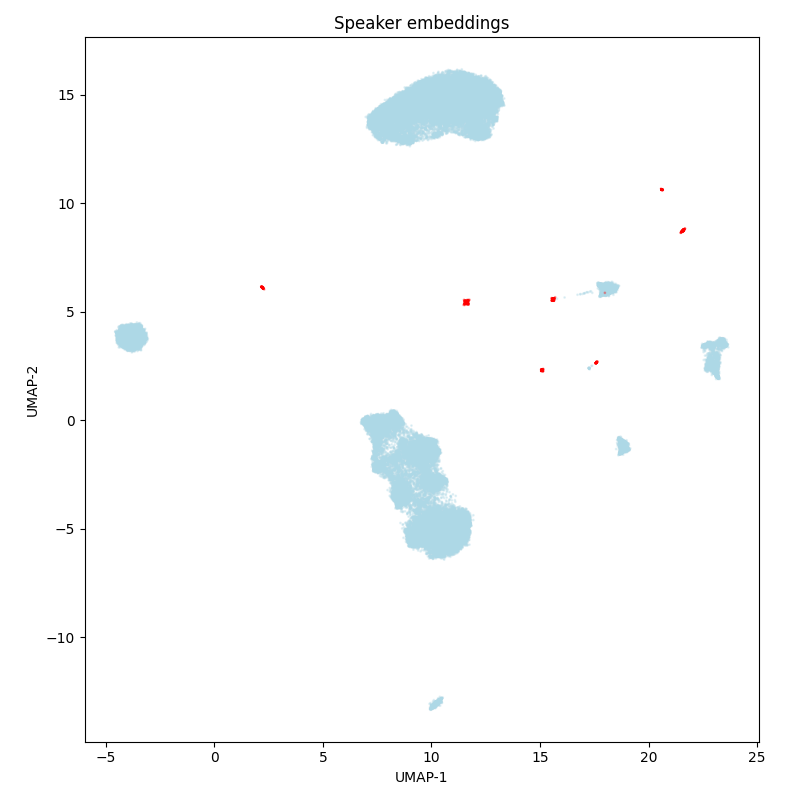
Sova¶
SOVA RuDevices is an acoustic corpus of approximately Russian live speech with manual annotating, prepared by SOVA.ai team. The dataset seems to be sourced from voice messages between people. The speech contains low to moderate audio quality, many colloquialisms, disfluencies. There are also problems with inaccurate audio cutting in some samples. Due to the large amount of disfluencies and poorly heard speech, the labeling is ambiguous in many samples (see the ours multivariant version below).
According to the speaker embedding UMAP-projections, there are a lof of speakers, but among them several dozens of the speakers occur repeatedly, and overlap between the train and test sets. There is also a possibility that all the speakers are repeated multiple times, but this is simply not visible due to the UMAP properties (they all merge into one big cluster).
Name |
sova-rudevices |
|---|---|
Splits |
test - 5542 samples, 5.54 hours (after removing 257 duplicates)
train - 79517 samples, 80.21 hours (after removing 2090 duplicates)
validation - 5532 samples, 5.56 hours (after removing 303 duplicates)
|
Source |
|
Language |
Russian |
Lengths |
Audio lengths from 1.0 s to 10.0 s, typically from 1.9 s to 5.2 s
|
Speakers |
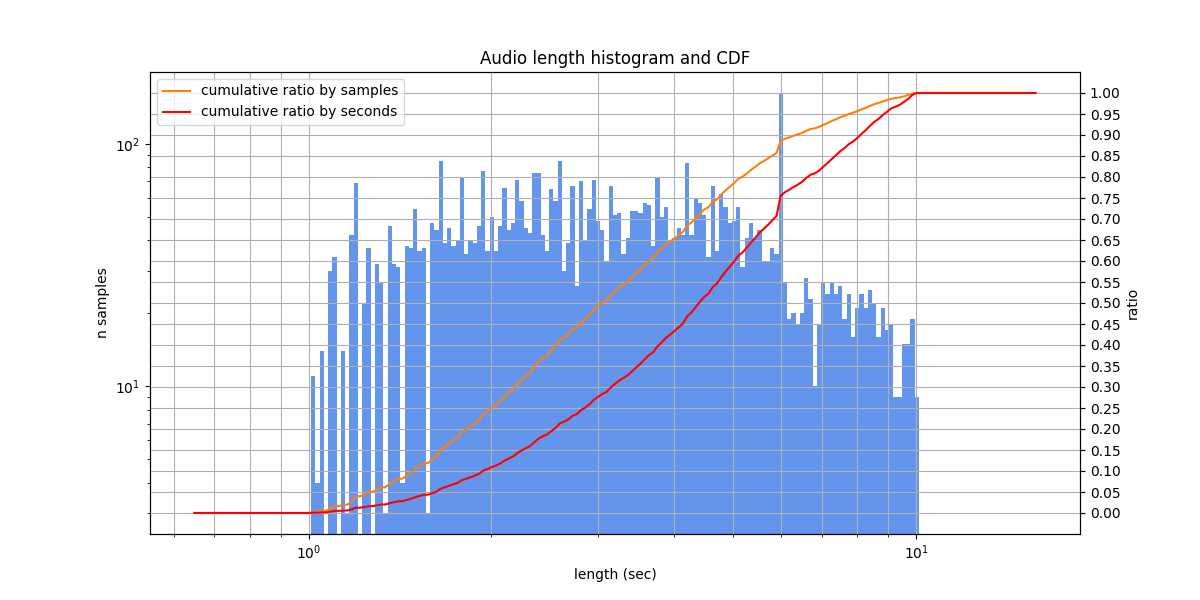
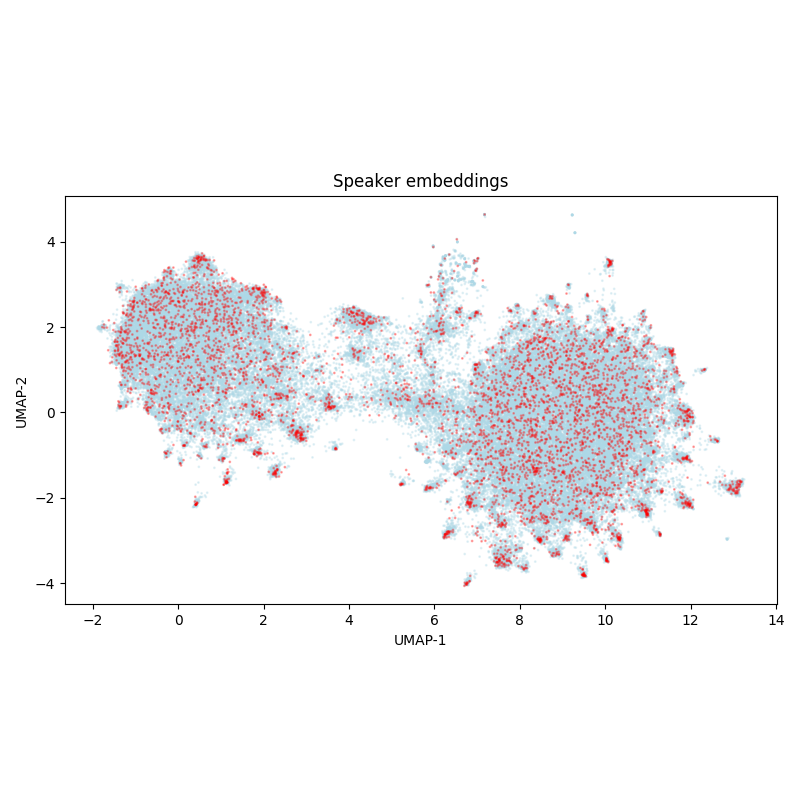
We also provide a version with multivariant relabeling. The relabeling was manual from scratch, without looking at the original or machine transcriptions. Due to the dataset properties, it is very different from the original version: 124 of 236 samples contain multivariant blocks.
In addition, we provide a sova-rudevices-single-variant dataset, that is a subset of sova-rudevices with samples included in sova-rudevices-multivariant, to enable direct side by side comparision.
Name |
sova-rudevices-multivariant |
|---|---|
Splits |
test - 250 samples, 0.27 hours
|
Source |
asr_eval/_data/relabelings/sova-rudevices.txt |
Language |
Russian |
Lengths |
Audio lengths from 1.1 s to 9.9 s, typically from 1.9 s to 6.0 s
|
Speakers |
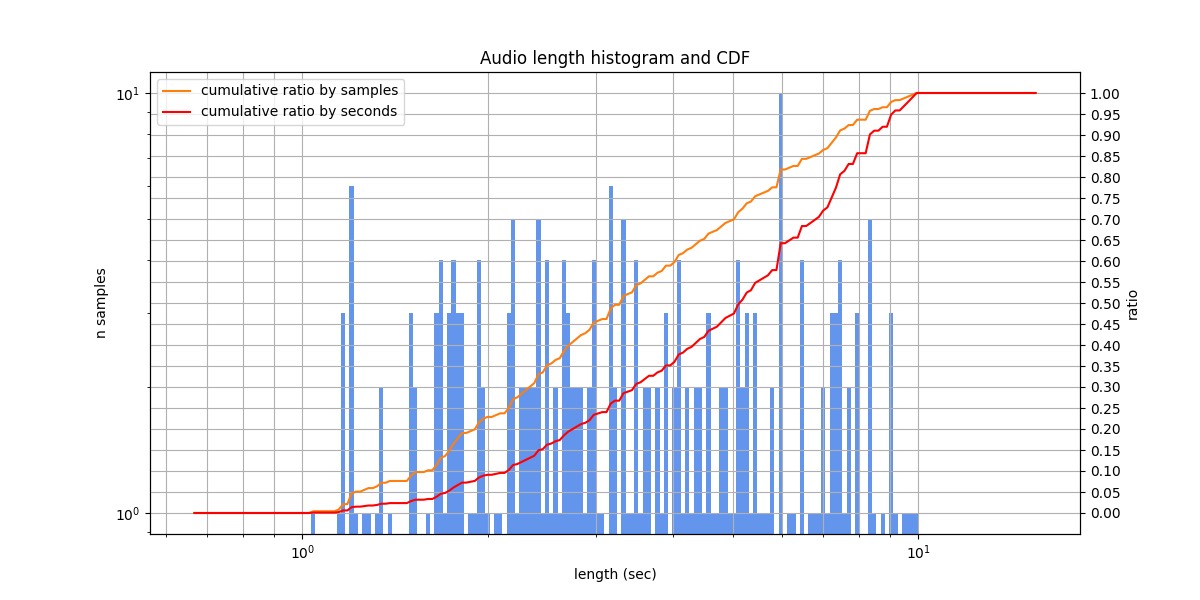
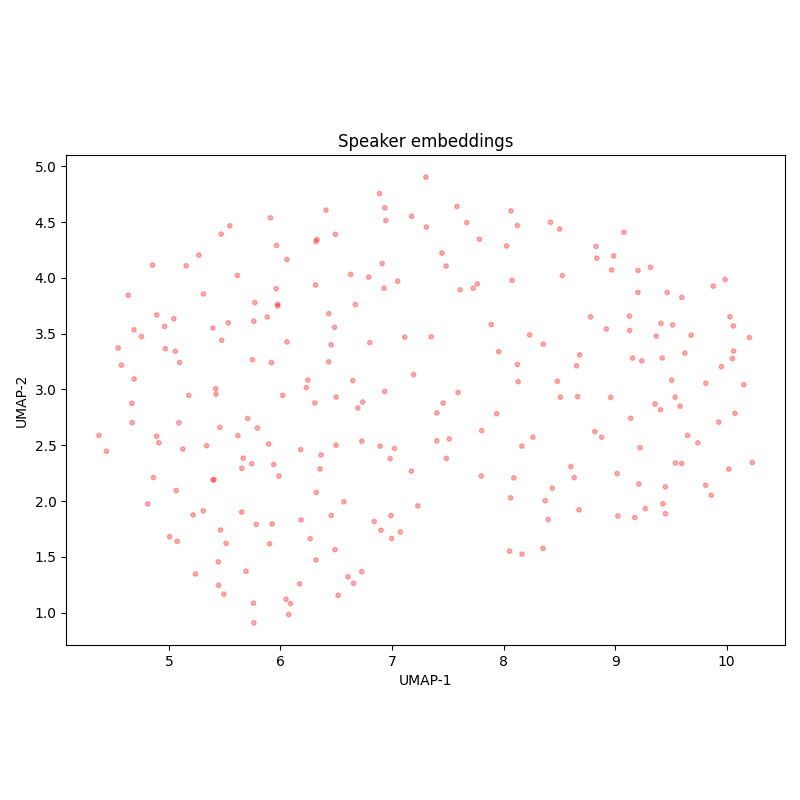
SOVA RuDevices Audiobooks is a Russian audiobooks dataset, prepared by SOVA.ai team. The audio conditions are not perfect, compared to the professionally read audiobooks).
According to the speaker embedding UMAP-projections, there are more than a hundred of speakers, however, around a dozen of them are found much more frequently than others. Importantly, all the speakers (and possibly the audiobooks) overlap between the train and test sets.
Name |
sova-rudevices-audiobooks |
|---|---|
Splits |
test - 20230 samples, 27.33 hours (after removing 85 duplicates)
train - 182551 samples, 247.29 hours (after removing 284 duplicates)
|
Source |
https://huggingface.co/datasets/dangrebenkin/sova_rudevices_audiobooks |
Language |
Russian |
Lengths |
Audio lengths from 0.8 s to 29.4 s, typically from 3.2 s to 6.3 s
|
Speakers |
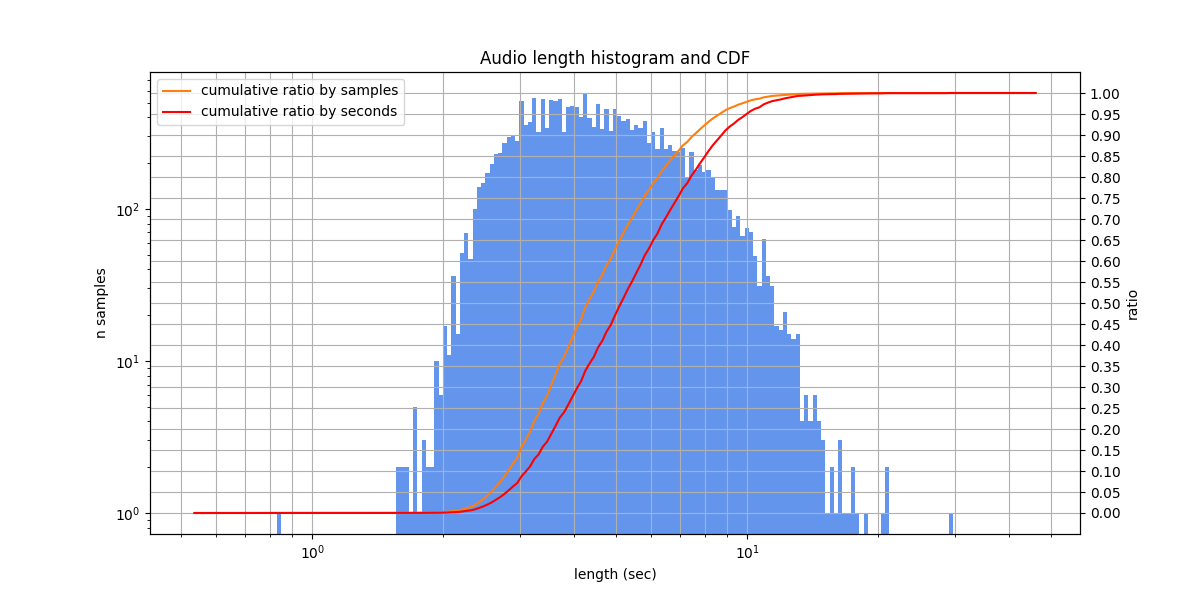
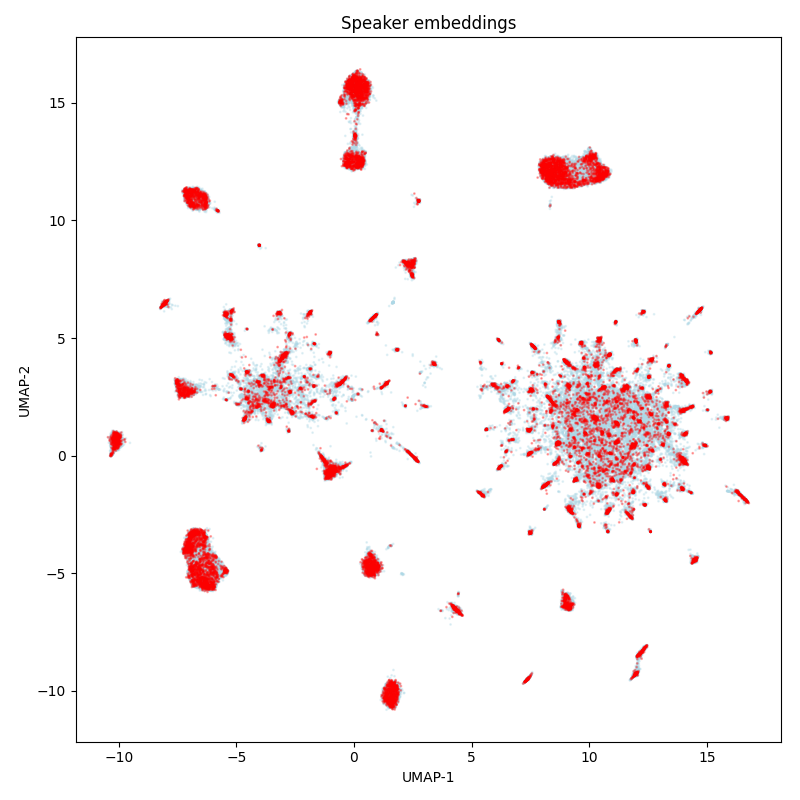
Speech Massive¶
A multilingual Spoken Language Understanding dataset, covers 12 languages (here we use only the Russian subset). The samples look like requests to virtual assitants, being spoken very clearly. There are no disfluencies and few background noises, indicating that the samples were recorded under controlled conditions. Often there are samples with numbers and names that could be written in Russian or English, which can complicate evaluation. There are also some labeling errors.
The diversity of speakers is moderate: there are dozens of speakers and they do not overlap between the train and test sets.
Name |
speech-massive-ru |
|---|---|
Splits |
test - 2974 samples, 3.44 hours
train_115 - 115 samples, 0.12 hours
validation - 2033 samples, 2.25 hours
|
Source |
|
Language |
Russian |
Lengths |
Audio lengths from 1.0 s to 29.9 s, typically from 2.9 s to 5.2 s
|
Speakers |
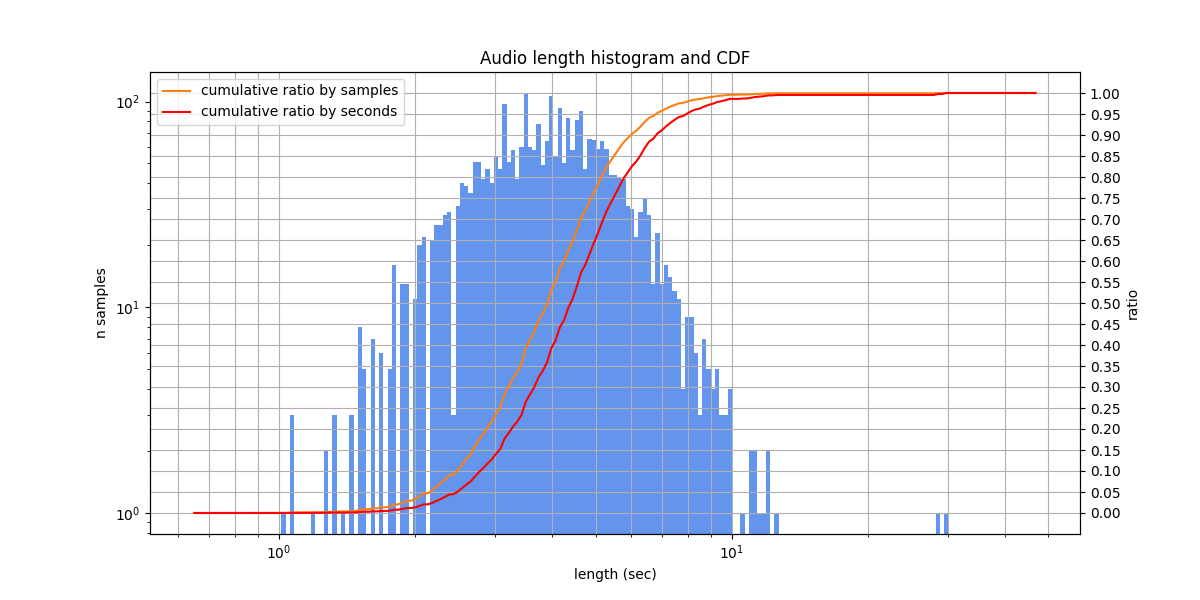
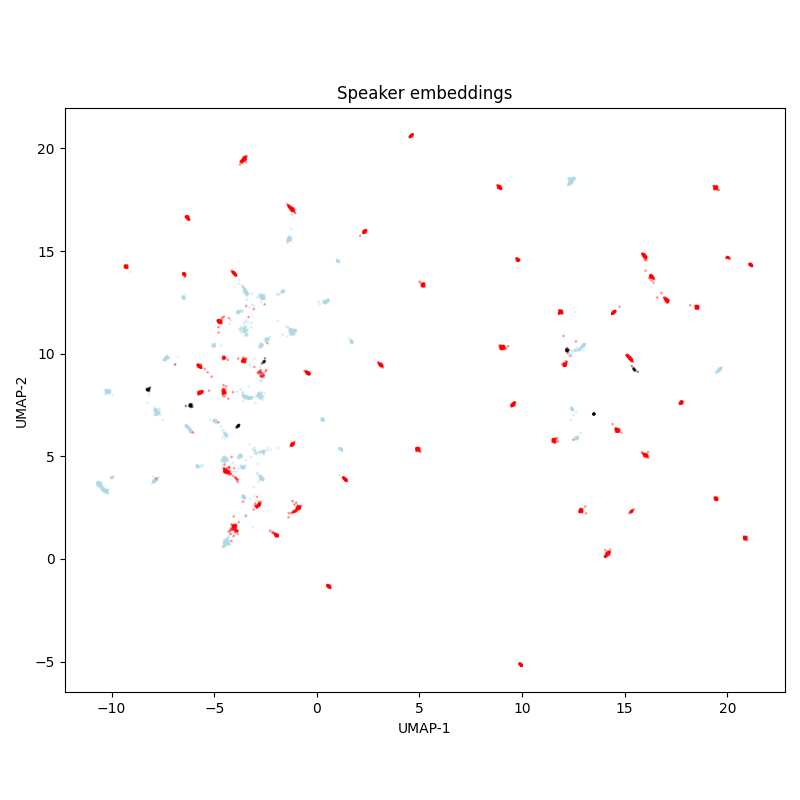
Toloka VoxDIY RusNews¶
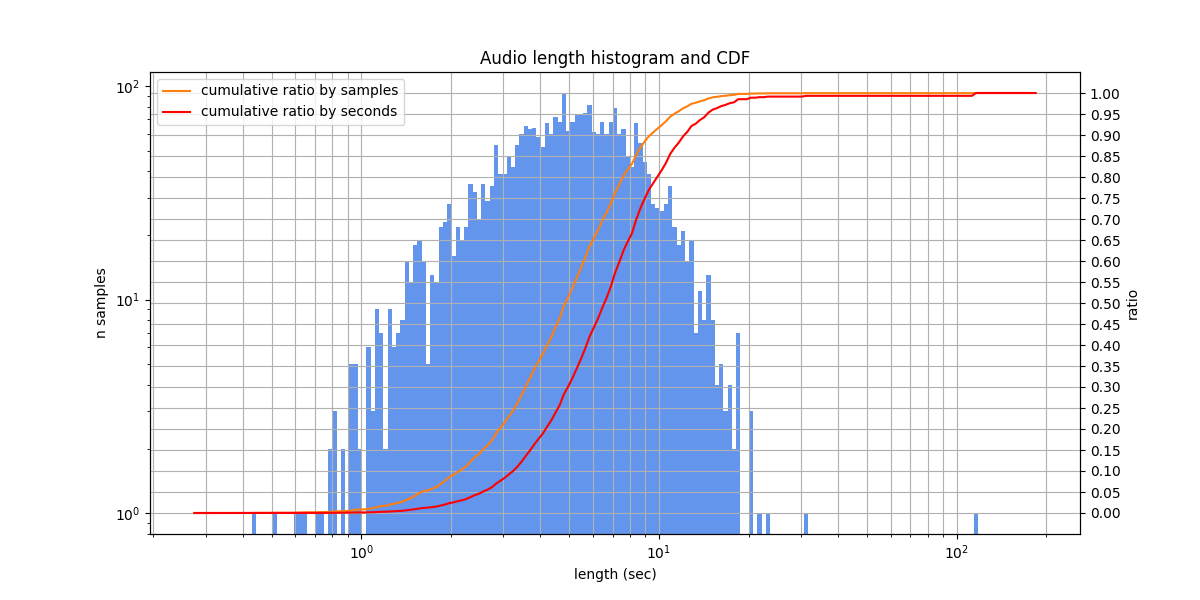
A dataset of crowdsourced audio transcriptions in Russian language (possibly an acronym for “Do It Yourself”). The dataset was constructed by annotating audio recordings of Russian sentences from the news domain on the Toloka crowdsourcing platform. The speakers read aloud news-style texts, at a medium or slow pace, without disfluencies or noises. In the labeling, numbers are written as words.
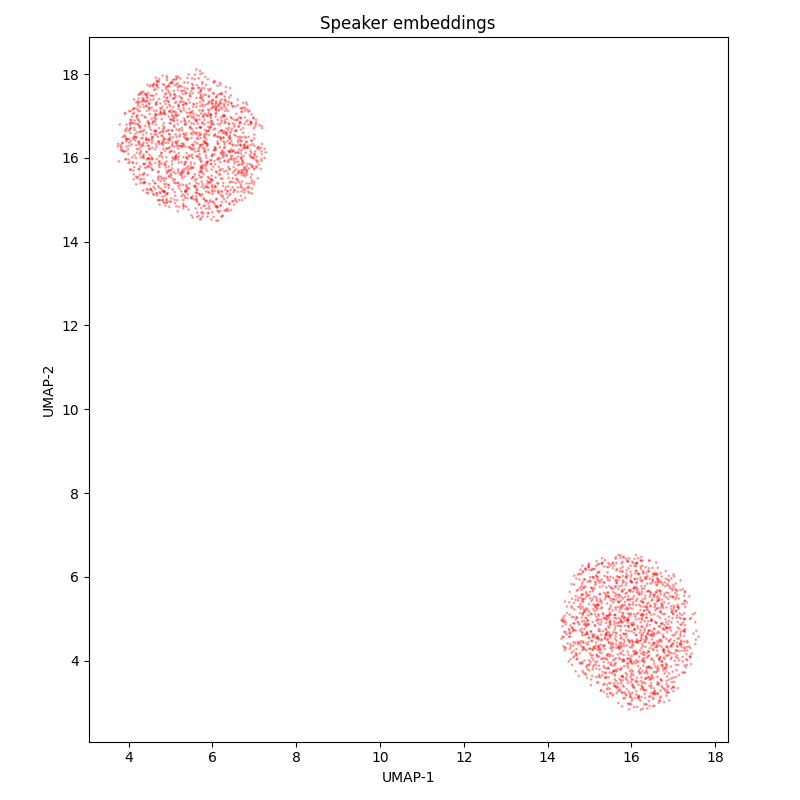
The diversity of speakers is extremely low: there seem to be only a single male speaker and a single female speaker.
To prepare the dataset run asr_eval.bench.datasets.toloka.prepare_toloka_VoxDIY_RusNews().
Name |
toloka-voxdiy-rusnews |
|---|---|
Splits |
test - 3090 samples, 4.78 hours (after removing 1 duplicate)
(the dataset has a single split called “test” in asr_eval and “train” on HF)
|
Source |
|
Language |
Russian |
Lengths |
Audio lengths from 0.4 s to 118.2 s, typically from 2.9 s to 7.7 s
|
Speakers |
Voxforge Ru¶
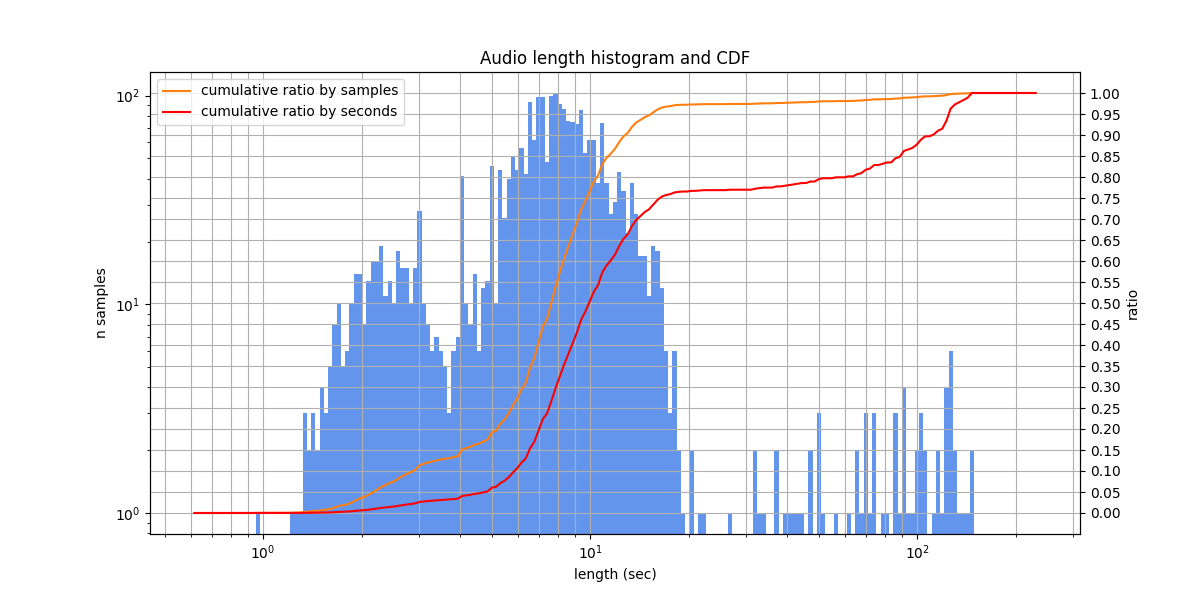
An open speech dataset, consists of user submitted audio clips submitted to the website (here we use only the Russian subset). Usually people read aloud different texts, the acoustic conditions are fine, however, there are exceptions. Around 10-20% of samples contain labeling errors.
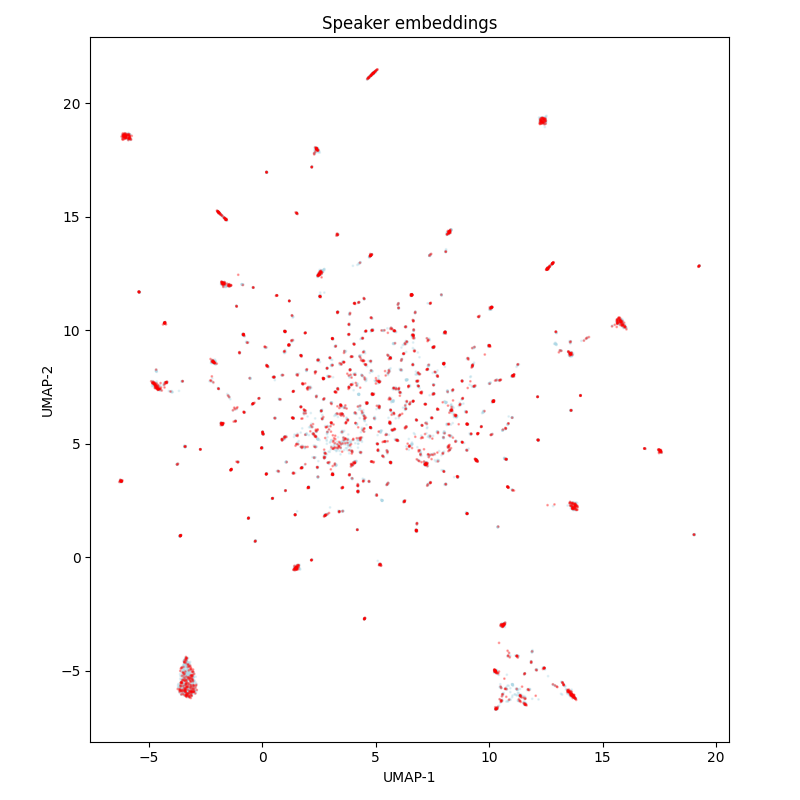
The diversity of speakers is high, but some speakers seem to overlap between the train and test sets.
Name |
voxforge-ru |
|---|---|
Splits |
test - 2644 samples, 7.23 hours (after removing 1 duplicate)
train - 6168 samples, 17.20 hours (after removing 1 duplicate)
|
Source |
https://huggingface.co/datasets/dangrebenkin/voxforge-ru-dataset |
Language |
Russian |
Lengths |
Audio lengths from 1.0 s to 147.5 s, typically from 5.2 s to 10.6 s
|
Speakers |
Yandex commands¶
A dataset from the Yandex Cup 2021 challenge, where the task was to recognize a fixed set of keywords. Preparing:
# a default cache dir is ~/.cache/asr_eval/datasets
# you can set a custom $ASR_EVAL_CACHE and pass it as env variable into Python
ASR_EVAL_CACHE=~/.cache/asr_eval/datasets
mkdir -p $ASR_EVAL_CACHE/datasets
cd $ASR_EVAL_CACHE/datasets
wget https://alphacephei.com/test-other/yacmd/yandex-cup-asr-data.tar.gz
tar -xvzf yandex-cup-asr-data.tar.gz && rm yandex-cup-asr-data.tar.gz
In the dataset, there is a labeled train split and unlabeled (private) test split. We only have a labeling for train split - hence the dataset name - and call this split “test” in asr_eval, because we use it for testing. It is worth considering that some models could be trained on these samples.
Each of the 38 words were spoken by approximately 3,000 people - the speaker diversity is very high. Every recording contain a single word - sometimes it is a number written as text in the labeling. We didn’t observe background noises or disfluencies in the labeled split we use.
The data was provided by Nikolai V. Shmyrev.
Name |
yandex-commands-train |
|---|---|
Splits |
test - 93282 samples, 76.83 hours
(this split is called “train” in the original data)
|
Source |
|
Language |
Russian |
Lengths |
Audio lengths from 2.5 s to 4.0 s, typically from 2.5 s to 3.5 s
|
Speakers |
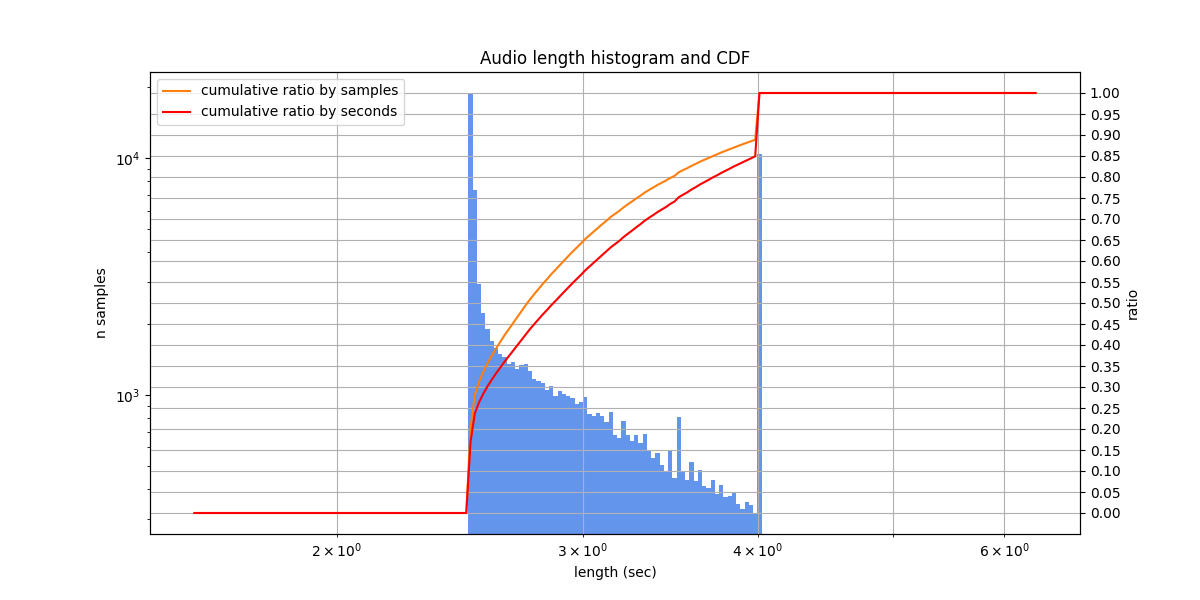
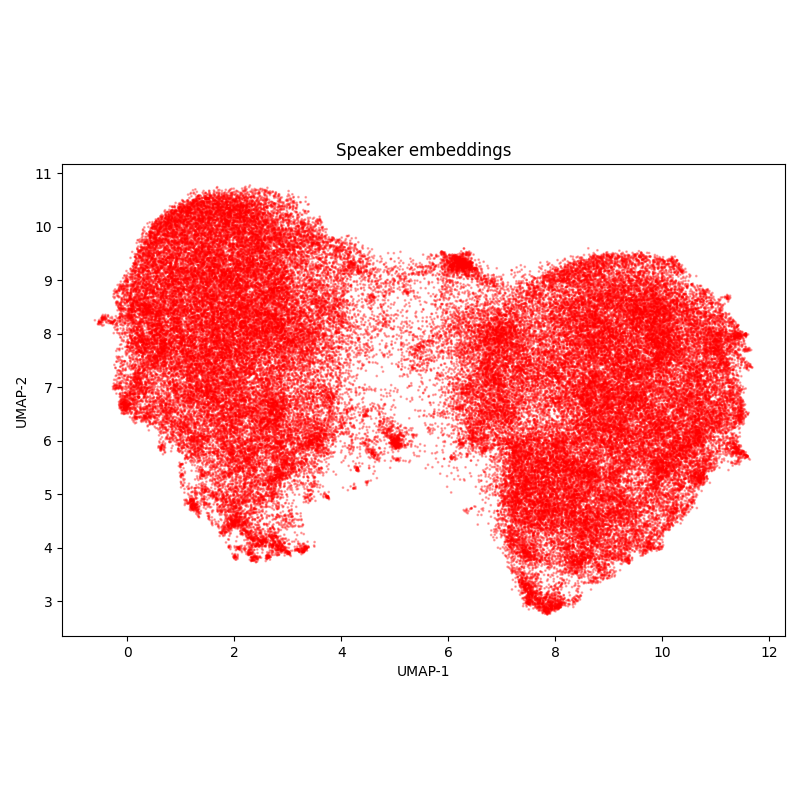
YouTube lectures¶
The dataset contains 7 annotated 15-30 minute Russian scientific lectures from YouTube, with varying quality, different speakers, and sometimes multiple speakers in a single recording. The labeling is single variant - this could imply problems with evaluating anglicisms, filler words, disfluencies, numbers etc.
Name |
youtube-lectures |
|---|---|
Splits |
test - 7 samples, 2.80 hours
(the dataset has a single split called “test” in asr_eval and “train” on HF)
|
Source |
https://huggingface.co/datasets/dangrebenkin/long_audio_youtube_lectures |
Language |
Russian |
Lengths |
Audio lengths from 1033.2 s to 1810.8 s, typically from 1218.9 s to 1743.8 s
|
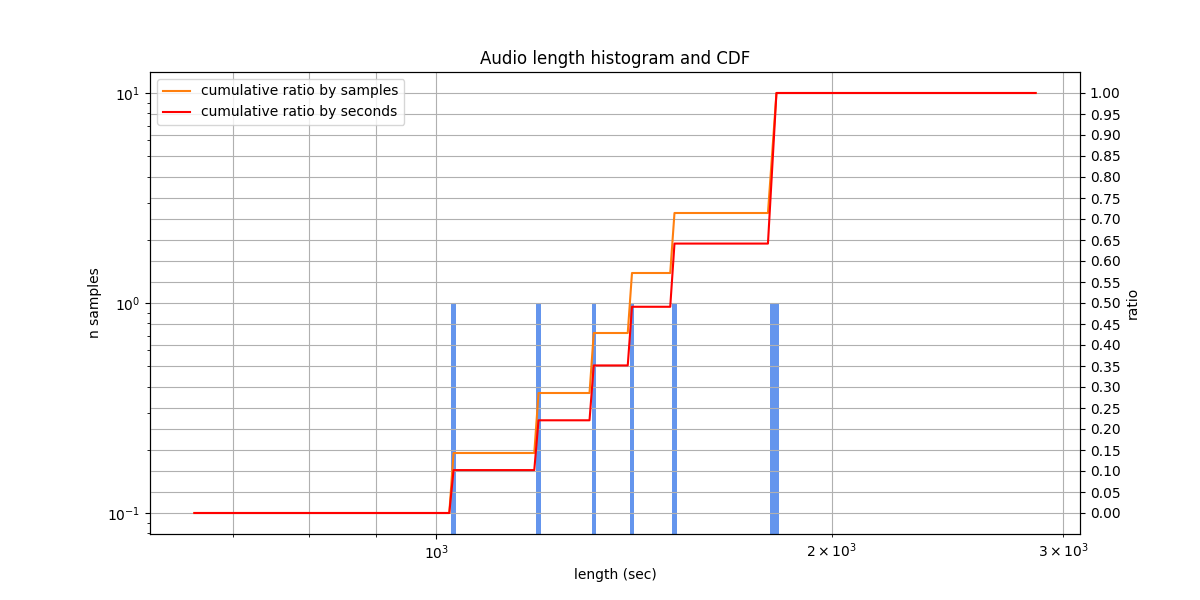
Datasets not included in asr_eval¶
The Common Voice dataset was previously hosted on Hugging Face, but was removed in late 2025. It is still possible to download it from the https://commonvoice.mozilla.org/, but there are major problems with it. According to the authors, the train-test split changes every version. It follows that the test split in every version contains samples from other versions’ train splits. Also, according to the authors, some models were trained on custom, non-standard train-test splits. Finally, every sample can we withdrawn from the dataset if a contributor revokes their consent to be included in the dataset. We suspect that these problems may cause heavy train-test leakage for some models, and test set inconsistency over time.
The PolyAI/minds14 dataset covers the e-banking domain, but the Russian subset looks like it was automatically labeled; about 30% of the examples contain labeling errors.
The Aniemore/resd_annotated Russian dataset for emotion recognition was sourced from 240 actors (the paper). The dataset contain emotional speech, occasionally from different actors in the same recording. However, the transcriptions seem to be automatic, obtained by the Whisper model, with many errors.
Reproducing the tables¶
To reproduce most of the information from these tables, run scripts/dataset_rst_table.py.